PostGIS in Action
About the Authors
Consulting
PostGIS in Action
About the Authors
Consulting
Thursday, January 24. 2008The Anatomy of PostgreSQL - Part 2 - Database ObjectsPrinter FriendlyRecommended Books: Beginning Databases with PostgreSQL PostgreSQL 2nd Edition (Douglas) In the first part of this series, The Anatomy of PostgreSQL - Part 1, we covered PostgreSQL Server object features. In this part, we shall explore the database and dissect the parts. Here we see a snapshot of what a standard PostgreSQL database looks like from a PgAdmin interface.
Catalogs and SchemasSchemas are a logical way of separating a database. They are designed simply for logical separation not physical separation. In PostgreSQL each database has a schema called public. For sql server people, this is equivalent to SQL Server's dbo schema. The default schema search path in postgresql.conf file is $user, public. Below are some fast facts and comparisons
Catalogs is actually a prefabrication of PgAdmin to make this distinction of calling Schemas that hold meta-like information "Catalogs". First Catalogs is a misnomer and in fact in some DBMS circles, Catalogs are another name for databases so its a bit confusing, but then some people (such as Old world Oracle - thought of the Database as the server and each schema as a separate database. So its all very confusing anyway.). We like to think of schemas as sub-databases. One may ask what is the difference between a "PgAdmin catalog" and a schema. The short-answer, as far as PostgreSQL is concerned, there isn't a difference. A PgAdmin catalog is a schema. In fact as far as we can tell, the schemas information_schema, pg_catalog, and pgagent are hard-wired in the PgAdmin logic to be grouped in something called Catalogs. The information_schema is a very important schema and is part of the ANSI standard, but is not quite so standard. It would be nice if all relational databases supported it, but they don't all do - MySQL 5, SQL Server (2000+), and PostgreSQL (7.4+) support them. Oracle and DB2 evidentally still don't, but there is hope. For the DBMS that support the information_schema, there are varying levels, but in all you can be pretty much assured to find tables, views, columns with same named fields that contain the full listings of all the tables in a database, listings of views and view definition DDL and all the columns, sizes of columns and datatypes. The pg_catalog schema is the standard PostgreSQL meta data and core schema. You will find pre-defined global postgres functions in here as well as useful meta data about your database that is very specific to postgres. This is the schema used by postgres to manage things internally. A lot of this information overlaps with information found in the information_schema, but for data present in the information_schema, the information_schema is much easier to query and requires fewer or no joins to arrive at basic information. The pg_catalog contains raw pg maintenance tables in addition to views while the information_schema only contains read-only views against the core tables. So this means with sufficient super rights and a bit of thirst for adventure in your blood, you can really fuck up your database or make fast changes such as moving objects to different schemas, by directly updating these tables, that you can't normally do the supported way. The other odd thing about the pg_catalog schema is that to reference objects in it, you do not have to schema qualify it as you would have to with the information_schema.
For example you can say To demonstrate - try creating a dummy table in the public schema with name pg_tables. Now if you do Casts, Operators, TypesAbility to define Casts, Operators and Types is a fairly unique feature of PostgreSQL that is rare to find in other databases. Postgres allows one to define automatic casting behavior and how explicit casts are performed. It also allows one to define how operations between different or same datatypes are performed. For creating new types, these features are extremely important since the database server would not have a clue how to treat these in common SQL use. For a great example of using these features, check out Andreas Scherbaum's - BOOLEAN datatype with PHP-compatible output For each table that is created, an implicit type is created as well that mirrors the structure of the table. ConversionsConversions define how characters are converted from one encoding to another - say from ascii_to_utf8. There isn't much reason to touch these or add to them that we can think of. If one looks under pg_catalog - you will find a hundred someodd conversion objects. DomainsDomains are sort of like types and are actually used like types. They are a convenient way of packaging common constraints into a data type. For example if you have an email address, a postal code, or a phone number or something of that sort that you require to be input in a certain way, a domain type would validate such a thing. So its like saying "I am a human, but I am a kid and need constraints placed on me to prevent me from choking on steak." Example is provided below
FunctionsThis is the container for stored functions. As mentioned in prior articles, PostgreSQL does not have stored procedures, but its stored function capability is in general much more powerful than you will find in other database management systems (DBMS) so for all intents and purposes, stored functions fill the stored procedure role. What makes PostgreSQL stored function architecture admirable is that you have a choice of languages to define stored functions in. SQL and PLPGSQL are the languages pre-packaged with PostgreSQL. In addition to those you have PLPerl, PLPerlU, PLPython, PLRuby, PLTCL, PLSH (shell), PLR and Java. In terms of ease of setup across all OSes, we have found PLR to be most friendly of setups. PLR on top of that serves a special niche in terms of analysis and graphing capability not found in the other languages. It opens up the whole R statistical platform to you. For those who have used SAS,S, and Matlab, R is of a similar nature so its a popular platform for scientists, engineers and GIS analysts. Operator Classes, Operator FamiliesOperator Classes are used to define how indexes are used for operator operations. PostgreSQL has several index options to choose from with the most common being btree and gist. It is possible to define your own internal index structure. If you do such a thing, then you will need to define Operator Classes to go with these. Also if you are defining a new type with a specialty structure that uses a preferred type of index, you will want to create an Operator Class for this. SequencesSequence objects are the equivalent of identity in Microsoft SQL Server and Auto Increment in MySQL, but they are much more powerful. What makes a sequence object more powerful than the former is that while they can be tied to a table and auto-incremented as each new record is added, they can also be incremented independent of a table. The same sequence object can also be used to increment multiple tables. It must be noted that Oracle also has sequence objects, but Oracle's sequence objects are much messier to use than PostgreSQL and Oracle doesn't have a slick concept of SERIAL datatype that makes common use of sequences easy to create and use. Sequence objects are automatically created when you define a table field as type serial. They can also be created independently of a table by executing
a DDL command of the form
If you wanted to manually increment a sequence - say in use in a manual insert statement where you need to know the id being assigned, you can do something of the following.
Here are some sequence fast facts
TablesWe've already covered sequences which can exist independent or dependent of tables. We already know tables hold data. Now we shall look at the objects that hang off of a table. Below is a snapshot of the payment table in Pagila demo database 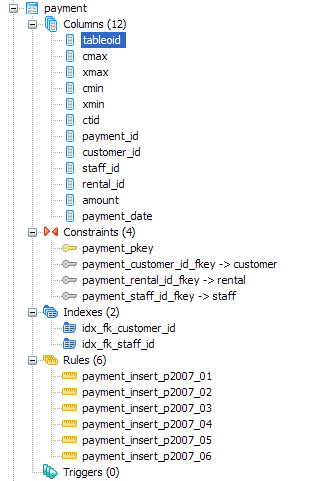
Columns - We all know what columns are. What is a little interesting about PostgreSQL - is that it has 6 system columns that every table has. These are tableoid, cmax, xmax, cmin, xmin, ctid and sometimes oid if you CREATE TABLE WITH OIDS. If you do a SELECT * on a table, you will never see these fields. You have to explicitly select them. The tableoid is the same for all records in a given table.
If you did a Rules - tables can have rules bound to them. In this case, the payment table has 6 rules bound to it, which redirect inserts to the child table containing the data that fits the date criterion. Using rules for table partitioning is a common use case in PostgreSQL. In other databases such as SQL Server Enterprise 2005 - this would be called Functional Partitioning and the equivalent to the PostgreSQL rules (in combination with contraints) would be equivalent to Partitioning Functions. Partitioning is only really useful for fairly large tables, otherwise the added overhead would probably not result in any speed gain and could actually reduce speed performance. PostgreSQL partitioning strategy is fairly simple and easy to understand when compared to some high-end commercial databases. In PostgreSQL 8.4 this strategy will probably become more sophisticated. Triggers - PostgreSQL allows one to define Triggers on events BEFORE INSERT/UPDATE, AFTER INSERT/UPDATE and for EACH ROW or EACH STATEMENT. The minor restriction in PostgreSQL is that the trigger body can not be written directly in the trigger envelop. The trigger envelop must call a triggering function and the triggering function is a special kind of function that returns a trigger. Indexes, Keys and Foreign Key Constraints - These objects are equivalent and behave the same as in other databases. PostgreSQL support referential integrity constraints and CASCADE UPDATE/DELETE on these. ViewsLast but not least, our favorite - Views. Views are the best thing since sliced-bread. They are not tables but rather saved queries that are presented as tables (Virtual Tables). They allow you to do a couple of interesting things
Trackbacks
Trackback specific URI for this entry
No Trackbacks
Comments
Display comments as
(Linear | Threaded)
You state that postgresql does not allow setting a default schema for each user, however this is not exactly correct. Since the search_path is defined as a GUC, you can set this search_path for each user using the alter role command:
ALTER ROLE xzilla set search_path = 'wizbang'; You can do this for any or all roles as needed, and other roles will pick up either the database default or cluster default.
Thanks for the clarification. We have made updates to our article to reflect that :-)
Great! simple descriptions with technical depth. This is golden. .thanks (from a PostGIS user who is new to Postgres)
|
Entry's LinksQuicksearchCalendar
Categories
SubscribeBlog Administration |
|||||||||||||||||||||||||||||||||||||||||||||||||