Monday, May 21. 2012PostgreSQL 9.2 Native JSON type supportPrinter FriendlyRecommended Books: PostGIS in Action PostgreSQL: Up and Running
PostgreSQL 9.2 pg_dump enhancementsPrinter FriendlyOne of the things I'm excited about in PostgreSQL 9.2 are the new pg_dump section - pre-data, data, and post-data options and the exclude-table-data option. Andrew Dunstan blogged about this briefly in pg_dump exclude table data. What is also nice is that pgAdmin III 1.16 supports the section option via the graphical interface The 9.2 pg_restore has similar functionality for restoring specific sections of a backup too. So what is all this section stuff for. Well it comes in particularly handy for upgrade scripts. I'll first explain what the sections mean and a concrete example of why you want this.
Continue reading "PostgreSQL 9.2 pg_dump enhancements" Wednesday, May 09. 2012File FDW Family: Part 2 file_textarray_fdw Foreign Data WrapperPrinter Friendly |
QuicksearchCalendarCategories
ArchivesSubscribeBlog Administration |



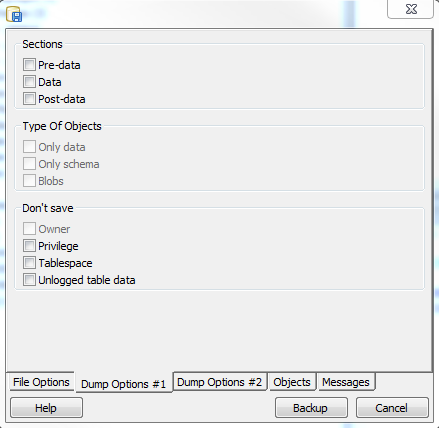 . I was a bit disappointed not to find the exclude-table-data option in pgAdmin III interface though.
The other nice thing about this feature is that you can use the PostgreSQL 9.2 dump even against a 9.1 or lower db and achieve the same benefit.
. I was a bit disappointed not to find the exclude-table-data option in pgAdmin III interface though.
The other nice thing about this feature is that you can use the PostgreSQL 9.2 dump even against a 9.1 or lower db and achieve the same benefit.
