Table Of Contents
Schemas vs. Schemaless structures and The PostgreSQL Type Farm
Feature or Frustration
Working with Timezones Intermediate
PLV8JS and PLCoffee Part 1: Upserting Intermediate
PLV8JS and PLCoffee Part 2: JSON search requests Intermediate
Building on MingW and deploying on VC compiled PostgreSQL Why and Why not
Creating GeoJSON Feature Collections with JSON and PostGIS functions
From the Editors
PostgreSQL: Up and Running book officially out
Our new book PostgreSQL: Up and Running is officially out. It's available in hard-copy and e-Book version directly from O'Reilly, Safari Books Online and available from Amazon in Kindle store. It should be available in hard-copy within the next week or so from other distributors.
Sadly we won't be attending OSCON this year, but there are several PostgreSQL talks going on. If you are speaking at a talk or other PostgreSQL related get together, and would like to give out some free coupons of our book or get a free e-book copy for yourself to see if it's worth effort mentioning, please send us an e-mail: lr at pcorp.us .
Our main focus in writing the book is demonstrating features that make PostgreSQL uniquely poised for newer kinds of workflows with particular focus on PostgreSQL 9.1 and 9.2. Part of the reason for this focus is our roots and that we wanted to write a short book to get a feel for the audience. We started to use PostgreSQL in 2001 because of PostGIS, but were still predominantly SQL Server programmers. At the time SQL Server did not have a spatial component that integrated seamlessly with SQL. As die-hard SQLers, PostGIS really turned us on. As years went by, we began to use PostgreSQL not just for our spatial apps, but predominantly non-spatial ones as well that had heavy reporting needs and that we had a choice of platform. So we came for PostGIS but stayed because of all the other neat features PostgreSQL had that we found lacking in SQL Server. Three off the bat are arrays, regular expressions, and choice of procedural languages. Most other books on the market just treat PostgreSQL like it's any other relational database. In a sense that's good because it demonstrates that using PostgreSQL does not require a steep learning curve if you've used another relational database. We didn't spend as much time on these common features as we'd like to in the book because it's a short book and we figure most users familiar with relational databases are quite knowledgeable of common features from other experience. It's true that a lot of people coming to PostgreSQL are looking for cost savings, ACID compliance, cross-platform support and decent speed , but as PostgreSQL increases in speed, ease of features, and unique features, we think we'll be seeing more people migrating just because its simply better than any other databases for the new kinds of workflows we are seeing today -- e.g. BigData analysis, integration with other datasources, leveraging of domain specific languages in a more seamless way with data.
So what's that creature on the cover?

It's an elephant shrew (sengi) and is neither an elephant nor a shrew, but closest in ancestry to the elephant, sea cow, and aardvark.
It is only found
in Africa (mostly East Africa around Kenya) and in zoos. It gets its name from its unusually long nose which it uses for sniffing out insect prey and keeping tabs on its mate. It has some other unusual habits:
it's a trail blazer building trails it uses to scout insect prey and also builds escape routes on the trail it memorizes to escape from predators. It's monogamous, but prefers to keep separate quarters from its mate. Males
will chase off other males and females will chase off other females. It's fast and can usually out-run its predators.
From the Editors
Schemas vs. Schemaless structures and The PostgreSQL Type Farm
There has been a lot of talk lately about schemaless models touted by NoSQL groups and how PostgreSQL fits into this New world order. Is PostgreSQL Object-Relational? Is it Multi-Model. We tend to think of PostgreSQL as type liberal and it's liberalness gets more liberal with each new release. PostgreSQL is fundamentally relational, but has little bias about what data types define each column of related tables. One of PostgreSQL great strengths is the ease with which different types can coexist in the same table and the flexible index plumbing and plan optimizer it provides that allows each type, regardless of how wild, to take full advantage of various index strategies and custom index bindings. Our 3 favorite custom non-built-in types we use in our workflow are PostGIS (of course), LTree (Hierarchical Type), and HStore (Key-Value type). In some cases, we may use all 3 in the same database and sometimes the same table - where we use PostGIS for spatial location, LTree for logical location, and Hstore just to keep track of random facts about an object that are easier to access than having a separate related table and are too random to warrant devoting a separate column for each. Sometimes we are guilty of using xml as well when we haven't figured out what schema model best fits a piece of data and hstore is too flat of a type to work. The advent of JSON in PostgreSQL 9.2 does provide for a nested schema-less model similar to what the XML type offers, but more JavaScript friendly. I personally see JSON as more of a useful transport type than one I'd build my business around or a type you'd use when you haven't figured out what if any structure is most suitable for your data. When you have no clue what structure a piece of data should be stored, you should let the data tell you what structure it wants to be stored in and only then will you discover by storing it in a somewhat liberal fashion how best to retrofit in a more structural self-descriptive manner. Schemas are great because they are self-describing, but they are not great when your data does not want to sit in a self-described bucket. You may find in the end that some data is just wild and refuses to stay between the lines and then by all means stuff it in xml or json or create a whole new type suit it feels comfortable in.
From the Editors
Feature or Frustration
Lately I'm reminded that one person's feature is another person's frustration. I've been following Paul's PostGIS Apologia detail about why things are done a certain way in PostGIS in response to Nathaniel Kelso's: A friendlier PostGIS? Top three areas for improvement. I've also been following Henrik Ingo: comparing Open Source GIS Implementation to get a MySQL user's perspective on PostGIS / PostgreSQL. Jo Cook has some interesting thoughts as well in her PostGIS for beginners amendment to Paul's comments. I have to say that both Nathaniel, Henrik, Jo and commenters on those entries have overlapping frustrations with PostgreSQL and PostGIS. The number one frustration is caused by how bad a job we do at pointing out avenues to get a friendly installation experience. I do plan to change this to at least document the most popular PostGIS package maintainers soon.
One of the things that Henrik mentioned was his frustration with trying to install PostGIS via Yum PostgreSQL repository and in fact not even knowing about the PostgreSQL Yum repository that has current and bleeding versions of PostgreSQL. I was surprised he didn't know because as a long-time user of PostgreSQL, I dismissed this as common knowledge. This made me realize just how out of touch I've become with my former newbie self and I consider this a very bad thing. I was also very surprised about another feature he complained about - CREATE EXTENSION did not work for him because he accidentally installed the wrong version of PostGIS in his PostgreSQL 9.1. The main reason for his frustration was something I thought was a neat feature of PostGIS. That is that PostGIS is not packaged into PostgreSQL core and you can in fact have various versions of PostGIS installed in the same PostgreSQL cluster. This unlike the other OGC spatial offerings of other databases (SQL Server, Oracle, MySQL) allows the PostGIS dev group to work on their own time schedule largely apart from PostgreSQL development group pressures. It also means we can take advantage of breaking changes introduced in PostGIS 2.+ for example without impacting existing apps people have running 1.5 and also allow people to take advantage of newer features even if they are running an earlier PostgreSQL version.
There is a frustrating side to this. PostGIS is built on other software and gives you the option of leaving features out. So it's a pluggable system designed to be
installed on yet another pluggable system. On the good side many of the PostGIS developers are also developers of said core dependencies; GEOS and GDAL in particular and PostgreSQL, mostly in support, but Mark and Paul have been
known to throw some money and elbow grease on the PostgreSQL code side to get supporting features implemented faster).
This good also hurts us because we assume people are intimately aware of how all these packages work together. It also means PostGIS
isn't available out of the box like the other spatial features of other databases.
So you'll see Sandro for example plugging in some feature
in latest GEOS development version and then plug in logic in latest PostGIS version to take advantage of this new feature.
We have GEOS, Proj, and now GDAL (and did I mention GDAL has dependencies too which are optional).
This GDAL entanglement drove Devrim nuts in fact when I begged him to include raster support in his
packages and I am extremely greatful to him (and still owe him that tutorial). All that wouldn't be so bad except for the fact that for GEOS and GDAL depending on which version you use and what you have packaged in,
what you can do with PostGIS is different. Some functions in PostGIS are disabled for example if you are using GEOS < 3.3 in 2.0 and similar goes for PostGIS 2.1, if you are using
GEOS < 3.4 (which is not even released yet), you are missing out on some pretty slick stuff. You can compile without GDAL if you don't want raster support, but you also won't get CREATE EXTENSION if you didn't compile with raster.
If you are a savvy Linux user like Sandro Santilli who can't see why he should upgrade his PostgreSQL to beyond PostgreSQL 8.4
and is very suspicious of anything as magical looking as CREATE EXTENSION, you might marvel in this wonderful freedom we offer the end user. Sorry for picking on you Sandro :). Many users don't like freedom especially if they are casual users of a piece of software.
If you are a package maintainer you like things that have no dependencies or at least things you can isolate so that it doesn't screw up any other software people might be running. Gathering from the frustrations people have had packaging, I have to say I suspect making these kinds of isolations is easier under windows than it is on most other platforms. I was under the assumption that packaging under windows was the hardest task and if we, as windows package maintainers can do it, then any maintainer can. Watching Devrim's frustration made me realize this may not be the case. In windows we had no issue isolating GDAL dependencies by changing our path variables during compile and leaving out extra raster drivers that required additional dependencies. While we have binaries for both x64bit and x32bit for various versions of PostgreSQL, the same set of binaries work from Windows 2003/Windows XP - Windows 2008/Windows 7. Seems other people especially Mac have to worry about different versions of Mac and stuff.
The balancing act
In any project, particularly open source, you have four key user groups and its really hard to satisfy one without pissing another off.
- Package Maintainers - want minimal dependencies and at same time maximize on features (would be nice to get paid too :) )
- Newbies - What can you do for me and you've got 5 minutes before I lose interest (elevator pitch) and if I run into issues installing you've lost me as a customer. If my first query doesn't work, you may lose me as a customer.
- Intermediate, Power Users - want the features packaged in they use -- Give me no less and preferably no more and please don't do TOO much for me. Give me some room to think.
- Project developers - want everyone to be happy and to have people show their appreciation by paying them or spreading the gospel of what a great piece of software they have created which makes the world a nicer place to live in
For a Project, the two main groups you have to satisfy are Package Maintainers and Newbies. Package Maintainers are the life-blood of your project and newbies are your next generation. Maintainers are your manufacturing department. If your software requires compilation, all you have is useless code for the large majority of users if you don't have package maintainers. Maintainers can make your software easy to install for the Newbies and provide an expedient and pleasurable upgrade path for your Intermediate and Power Users. As I said before you want everyone using the latest version of your software just for simplicity of maintainence. Although I think Package Maintainers are the most important group, and their contributions are sadly often overlooked, you can't listen to them blindly. You want their packaging to have the bells and whistles you expect a lot of users to demand. Sometimes that additional packaging is hard, and requires guidance from the development group and user community. You don't want a user for example saying Hey I got raster support on windows, why don't I have that when I deploy on CentOS or Ubuntu, or how come I have this function on windows and not on RedHat install. On the other side of the fence, you have those people that complain: I only use geometry and geography, why do I have to put up with these raster functions to confuse me. In fact I don't need anything but geography because I just want simple location search..
I admit as a PostGIS project, I think we've pretty much sucked at making package maintainers lives easier by not guiding them on topics such as requisite dependencies , consistent user experience, things to watch out for with dependencies, how important we feel a feature is to package in, and MOST IMPORTANTLY broadcasting their package availability. We've essentially as Paul said dismissed it as someone else's problem and users should bug their maintainers if they want newer PostGIS supported. This especially depresses me since that's the group I feel most a part of.
Your software has too many features
The best kind of software is software that doesn't need explanation or documentation. The more features you pile on, the harder it is to hide those features until the user is ready to digest them. You'll gain some new converts with more features , but you'll also get a lot of people leaving you or dismissing you because your software is too complicated to operate or much too much baggage for the little they want to do.
To a large extent as much as we try with making PostgreSQL or PostGIS easy to use and understand by newcomers, it's just going to be too complicated for a large majority of users and they'll pick something else that doesn't require reading 200 pages to wrap their mind around or that is more aligned with the mode of thinking they are used to. The only undisputable feature is speed. Speed may not be the sexiest thing but it sells if you can showcase it well. You'll win converts because they will be willing to put up with having too many features, and a somewhat cumbersome install, if you can convince them they'll get more speed than they can with any other product.
What's new and upcoming in PostgreSQL
PLV8JS and PLCoffee Part 1: Upserting Intermediate
Today's modern web application workflow in its simplest form looks something like this:
- Get dataset as JSON object usually using yet another JSON query object to pass the request using a javascript framework like JQuery/ExtJS/OpenLayers/Leaflet etc.
- Make changes to JSON dataset object and send back to the web server.
- On webserver unravel the JSON object and save to respective database tables. This part is really yucky as it often involves the web application server side language doing the unraveling and then yet another step of setting up stored procedures or other update logic to consume it.
We hate the way people build tiers for the same reason Cartman hates lines at the amusement park. Sure tiers are great for certain things like building connected microcosms, but most of the time they are overkill and if applied too early make your application needlessly complicated. In the end all we care about is data: serving data, analyzing data, getting good data and everything else is just peacock feathers.
The introduction of JSON type support in PostgreSQL 9.2 and languages PL/V8 (PL/Javascript) and its Pythoness-like twin PL/Coffee provides several options for bringing your data and application closer together since they have native support for JSON. In this first part we'll demonstrate one: An upsert stored procedure that takes a single JSON object instead of separate args and updates existing data and adds missing records. In later articles we'll show you the front end app and also add a sprinkle of PostGIS in there to demonstrate working with custom types.
Setting up the tables
We'll use this table and add more tables to this model in later articles:
CREATE TABLE inventory (prod_code varchar(20) primary key
, prod_name varchar(50)
, loc_id integer
, date_add timestamptz DEFAULT CURRENT_TIMESTAMP
, date_upd timestamptz DEFAULT CURRENT_TIMESTAMP
);
INSERT INTO inventory (prod_code, prod_name, loc_id)
VALUES ('BB1', 'Breadboard 174mm x 67mm', 1)
, ('SIR', 'Solder Iron', 2)
, ('TI_TMS5100', 'Texas Instruments TMS5100', 3);
The Upsert Stored procedure
PL/Javascript implementation
-- this will take a json dataset as input and do a data merge
CREATE OR REPLACE FUNCTION upsert_inventory(param_inv json) RETURNS
text AS $$
var o = JSON.parse(param_inv);
/** update plan **/
var uplan = plv8.prepare('UPDATE inventory SET prod_name = $1, loc_id = $2 WHERE prod_code = $3', ['text', 'int', 'text'] );
/** insert plan **/
var iplan = plv8.prepare('INSERT INTO inventory( prod_name, loc_id, prod_code) VALUES($1, $2, $3)', ['text', 'int', 'text'] );
var num_changed;
var num_ins = 0, num_upd = 0;
if (typeof o != 'object')
return NULL;
else {
for(var i=0; i<o.length; i++){
num_changed = uplan.execute([o[i].prod_name, o[i].loc_id, o[i].prod_code]);
num_upd += num_changed;
if (num_changed == 0){ /** we got no updates, so insert **/
num_changed = iplan.execute([o[i].prod_name, o[i].loc_id, o[i].prod_code]);
num_ins += num_changed;
}
}
}
iplan.free();
uplan.free();
return num_upd + ' record(s) updated and ' + num_ins + ' records inserted';
$$ LANGUAGE plv8 VOLATILE;
PL/CoffeeScript equivalent
CREATE OR REPLACE FUNCTION upsert_inventory(param_inv json) RETURNS
text AS $$
o = JSON.parse(param_inv)
# update plan
uplan = plv8.prepare("UPDATE inventory SET prod_name = $1, loc_id = $2 WHERE prod_code = $3", [ "text", "int", "text" ])
# insert plan
iplan = plv8.prepare("INSERT INTO inventory( prod_name, loc_id, prod_code) VALUES($1, $2, $3)", [ "text", "int", "text" ])
num_changed = undefined
num_ins = 0
num_upd = 0
unless typeof o is "object"
return NULL
else
i = 0
while i < o.length
num_changed = uplan.execute([ o[i].prod_name, o[i].loc_id, o[i].prod_code ])
num_upd += num_changed
if num_changed is 0 # we got no updates, so insert
num_changed = iplan.execute([ o[i].prod_name, o[i].loc_id, o[i].prod_code ])
num_ins += num_changed
i++
iplan.free()
uplan.free()
return num_upd + ' record(s) updated and ' + num_ins + ' records inserted'$$
LANGUAGE plcoffee VOLATILE;
Testing out the stored proc
-- this is to simulate data coming from jquery
-- or some other javascript client api
-- we aggregate all rows we want to change in an array
-- and then we convert the array of rows to
-- a single json object that will serve as our dataset
SELECT upsert_inventory(array_to_json(array_agg(inv)) )
FROM (SELECT replace(prod_name, 'Bread', 'Butter') As prod_name
, loc_id
, replace(prod_code, 'SIR', 'SIR2') as prod_code
FROM inventory ) As inv;
-- output of query --
2 record(s) updated and 1 records inserted
--Lets see what we have now --
SELECT prod_code, prod_name
FROM inventory ORDER BY prod_code;
prod_code | prod_name
------------+---------------------------
BB1 | Butterboard 174mm x 67mm
SIR | Solder Iron
SIR2 | Solder Iron
TI_TMS5100 | Texas Instruments TMS5100
Basics
Contiguous Ranges of primary keys: a more cross platform and faster approach Advanced
In last article Finding Contiguous primary keys we detailed one of many ways of finding continuous ranges in data, but the approach would only work on higher-end dbs like Oracle 11G, SQL Server 2012, and PostgreSQL 8.4+. Oracle you'd have to replace the EXCEPT I think with MINUS. It wouldn't work on lower Oracle because of use of CTEs. It wouldn't work on lower SQL Server because it uses window LEAD function which wasn't introduced into SQL Server until SQL Server 2012. Someone on reddit provided a Microsoft SQL Server implementation which we found particularly interesting because - it's a bit shorter and it's more cross-platform. You can make it work with minor tweaks on any version of PostgreSQL, MySQL, SQL Server and even MS Access. The only downside I see with this approach is that it uses correlated subqueries which tend to be slower than window functions. I was curious which one would be faster, and to my surprise, this version beats the window one we described in the prior article. It's in fact a bit embarrassing how well this one performs. This one finished in 462 ms on this dataset and the prior one we proposed took 11seconds on this dataset. Without further ado. To test with we created a table:
CREATE TABLE s(n int primary key);
INSERT INTO s(n)
SELECT n
FROM generate_series(1,100000) As n
WHERE n % 200 != 0;For those people who don't have the luxury of generate_series function, we've packaged the table as a bunch of inserts in s table
-- SQL Server implementation (any version)
SELECT
FirstInRange.n as start_n,
(SELECT TOP 1 n
FROM s as LastInRange
WHERE LastInRange.n > FirstInRange.n
AND not EXISTS(SELECT *
FROM s as NextInRange
WHERE NextInRange.n = LastInRange.n + 1)
ORDER BY n asc) as end_n
FROM s as FirstInRange
WHERE NOT EXISTS(SELECT *
FROM s as PreviousInRange
WHERE PreviousInRange.n = FirstInRange.n - 1);
To work on PostgreSQL (should work on MySQL and probably any database supporting limit) would require a minor adjustment:
-- PostgreSQL implementation (any version)
-- Should work on MySQL (any version) as well
SELECT
FirstInRange.n as start_n,
(SELECT n
FROM s as LastInRange
WHERE LastInRange.n > FirstInRange.n
AND NOT EXISTS(SELECT *
FROM s as NextInRange
WHERE NextInRange.n = LastInRange.n + 1)
ORDER BY n asc LIMIT 1) as end_n
FROM s as FirstInRange
WHERE not exists(SELECT *
FROM s as PreviousInRange
WHERE PreviousInRange.n = FirstInRange.n - 1);
Basics
Working with Timezones Intermediate
One of PostgreSQL's nice features is its great support for temporal data. In fact it probably has the best support for temporal data than any other database. We'll see more of this power in PostgreSQL 9.2 with the introduction of date time range types. One of the features we've appreciated and leveraged quite a bit in our applications is its numerous time zone aware functions. In PostgreSQL timestamp with time zone data type always stores the time in UTC but default displays in the time zone of the server, session, user. Now one of the helper functions we've grown to depend on is to_char() which supports timestamp and timestamp with timezone among many other types and allows you to format the pieces of a timestamp any way you like. This function is great except for one small little problem, it doesn't allow you to designate the display of the output timezone and always defaults to the TimeZone value setting of the currently running session. This is normally just fine (since you can combine with AT TIMEZONE to get a timestamp only time that will return the right date parts, except for the case when you want your display to output the time zone -- e.g. EDT, EST, PST, PDT etc (timestamp without timezone is timezone unaware). In this article we'll demonstrate a quick hack to get around this issue. First let's take to_char for a spin.
Using to_char
--We're in Boston
SELECT to_char(CURRENT_TIMESTAMP, 'Day Mon dd, yyyy HH12:MI AM (TZ)');
-- outputs--
Sunday Jul 08, 2012 11:07 AM (EDT)
set TimeZone='US/Central';
SELECT to_char(CURRENT_TIMESTAMP, 'Day Mon dd, yyyy HH12:MI AM (TZ)');
--output is --
Sunday Jul 08, 2012 10:07 AM (CDT)
--if you convert note how the TZ is no longer present --
-- because its just a timestamp
SELECT to_char(CURRENT_TIMESTAMP AT TIME ZONE 'America/Los_Angeles', 'Day Mon dd, yyyy HH12:MI AM (TZ)');
--output is --
Sunday Jul 08, 2012 08:07 AM ()
The function hack
We see we can change the time zone and have to_char register a date time for that time zone. One way which I admit is not that elegant is to wrap the set call in a function and then reset when done. It's not elegant mostly because it's not clear if there would be side issues resulting from this. In a parallel process there might be, but since PostgreSQL doesn't support parallel processing at this time, there shouldn't be.
set local instead of local which is a much better solution since it only changes the local state. We've crossed out ours and replaced with his revision.--Original function --
-- The function --
CREATE OR REPLACE FUNCTION date_display_tz(param_dt timestamp with time zone, param_tz text, param_format text)
RETURNS text AS
$$
DECLARE var_prev_tz text; var_result varchar;
BEGIN
-- store prior timezone so we can reset it back when we are done
SELECT setting INTO var_prev_tz FROM pg_settings WHERE name = 'TimeZone';
EXECUTE 'set timezone = ' || quote_literal(param_tz) ;
var_result := to_char(param_dt, param_format);
--reset time zone back to what it was
EXECUTE 'set timezone = ' || quote_literal(var_prev_tz) ;
return var_result;
END;$$
LANGUAGE plpgsql VOLATILE;
-- Simon Bertrang's version
-- uses local to obviate the need to reset the timezone
-- further refined with Bruce Momjian's suggestion to use set_config
-- instead of dynamic sql
CREATE OR REPLACE FUNCTION date_display_tz(param_dt timestamp with time zone, param_tz text, param_format text)
RETURNS text AS
$$
DECLARE var_result varchar;
BEGIN
EXECUTE 'set local timezone = ' || quote_literal(param_tz);
PERFORM set_config('timezone', param_tz, true);
var_result := to_char(param_dt, param_format);
RETURN var_result;
END;
$$ language plpgsql VOLATILE;
COMMENT ON FUNCTION date_display_tz(timestamp with time zone, text, text) IS 'input param_dt: time stamp with time zone
param_tz: desired output time zone
param_format: desired date output
This function will return the timestamp formatted using the time zone local time';
Now to take our new function for a test drive
-- we use the FM in front to get rid of the 9 char padding
SELECT tz_name, date_display_tz(CURRENT_TIMESTAMP, tz_name, 'FMDay Mon dd, yyyy HH12:MI AM (TZ)')
FROM (VALUES ('US/Eastern')
, ('US/Central')
, ('America/Los_Angeles') ) AS t(tz_name);
tz_name | date_display_tz --------------------+------------------------------------ US/Eastern | Sunday Jul 08, 2012 08:05 PM (EDT) US/Central | Sunday Jul 08, 2012 07:05 PM (CDT) America/Los_Angeles | Sunday Jul 08, 2012 05:05 PM (PDT)
PL Programming
Building PLV8JS and PLCoffee for Windows using MingW64 w64-w32 Advanced
As mentioned in our previous article Building on MingW deploying on VC we often build on MingW and deploy on Windows servers running EDB distributed VC PostgreSQL builds
for extensions we want that don't come packaged. One of the new ones we are really excited about is the PL/V8 and PL/Coffee ones. Could we do it
and would it actually work on a VC build. YES WE CAN and yes it does. I HAZ Coffee and a V8:  .
.
Here are some instructions we hope others will find useful. Even if you aren't on Windows, you might still find them useful since MingW behaves much like other Unix environments.
If you are on windows, and just want to start using PLV8 and PLCoffee. We have binary builds for both PostgreSQL 9.2 Windows 32-bit (pg92plv8jsbin_w32.zip) and PostgreSQL 9.2 Windows 64-bit (pg92plv8jsbin_w64.zip) which you should be able to just extract into your PostgreSQL 9.2 beta windows install. We quickly tested with EDB VC++ builds and they seem to work fine on standard VC++ PostgreSQL 9.2beta2 installs. We haven't bothered building for lower PostgreSQL, but if there is some interest, we'd be happy to try.
Building on MingW64 chain
- Download a binary of MingW64 if you don't have one already. I think you'll need one that has at least gcc 4.5. We are using a package that has gcc 4.5.4. Details of how we setup our environment are PostGIS 2.0 Mingw64 build instructions
- download Python27 (32-bit version we think you need 32-bit since scones seems to be only a 32-bit package its just a builder so will work fine for building your 64-bit install) (2.7.3) for windows from: http://www.python.org/download/windows/ and install. We usually install in C:\Python27 which is the default. The recommended is to use GYP instead of scons, but we couldn't get GYP to work. I think there is better support for GYP if building with VC++.
- Download scons installer (scons-2.1.0.win32.exe) from www.scons.org and install (in your Python27)
- Here is our build script for building the V8 engine
OS_BUILD=64 export PATH="/c/Python27:/c/Python27/Scripts:.:/bin:/include:/mingw/bin:/mingw/include:/c/Windows/system32:/c/Windows:/usr/local/bin:/c/ming${OS_BUILD}/svn" export PROJECTS=/c/ming${OS_BUILD}/projects export V8_REL=trunk cd ${PROJECTS}/v8 #you can manually just use subversion here svn checkout http://v8.googlecode.com/svn/${V8_REL}/ ${V8_REL} cd ${PROJECTS}/v8/${V8_REL} #if you are building for 32-bit mingw64-w32 change arch=x64 to arch=ia32 #note that newer versions of v8 require you to add the # I_know_I_shoud_build_with_GYP whereas older versions do not scons.py mode=release arch=x64 toolchain=gcc importenv=PATH library=shared I_know_I_should_build_with_GYP=yes #this builds the interactive shell console you can use for debugging #when building for plv8 #you will get a warning if d8.exe is not found #but doesn't seem to be needed for install scons.py d8 mode=release arch=x64 toolchain=gcc importenv=PATH library=shared #for release this will reduce size of dll strip *.dll - When you are done running a build script that looks something like above you should see two dlls in trunk folder (v8.dll, v8preparser.dll) and an executable d8.exe
- We really didn't want to pollute our mingw install, but these steps were required for the libraries and d8.exe to be found: Copy the v8.dll, v8prepare.dll to your mingw64/lib folder (or mingw32/lib)
- Copy v8.dll, v8prepare.dll, d8.exe to your mingw64/bin (or mingw32) folder
- Download the plv8 source code from git. The stale download files http://code.google.com/p/plv8js were no good and caused all sorts of frustrating Yield errors. I've asked Andrew Dunstan to update the zips so people who don't have Git can function. We used msysgit and TortoiseGit for downloading source.
- Open the Makefile and edit path of v8 code at top
- To get around error: undefined reference to `__cxa_throw' and also
failing in production when throwing an exception, had to compile lstdc++ statically
into the dll by doing this:
we also had to make this change To fix change Change line: SHLIB_LINK := $(SHLIB_LINK) -lv8 To: #this was our original attempt # but installchecks that threw js_error would crash the postgres back end
SHLIB_LINK := $(SHLIB_LINK) -lv8 -lstdc++#change CUSTOM_CC from g++ to gcc CUSTOM_CC = gcc #so we statically compiled in with this: SHLIB_LINK := $(SHLIB_LINK) -lv8 -Wl,-Bstatic -lstdc++ -Wl,-Bdynamic -lm #make sure this uses CUSTOM_CC instead of g++ %.o : %.cc ${CUSTOM_CC} $(CCFLAGS) $(CPPFLAGS) -I $(V8DIR)/include -fPIC -c -o $@ $< - Our shell script for compiling against PostgreSQL 9.2beta2 compiled mingw looks like
export PROJECTS=/c/ming64/projects export PG_VER=9.2beta2 export OS_BUILD=64 export PGPORT=8442 export PGUSER=postgres export PATH=".:/usr/local/bin:/mingw/bin:/bin:/c/Windows/system32:/c/Windows" export PATH="${PROJECTS}/pgx64/pg${PG_VER}w${OS_BUILD}/bin:${PROJECTS}/pgx64/pg${PG_VER}w${OS_BUILD}/lib:$PATH" cd ${PROJECTS}/postgresql/extensions/plv8js make clean USE_PGXS=1 make clean make ENABLE_COFFEE=1 install #for release this will reduce size of dll strip *.dll #make sure all tests pass #You will need to have your PostgreSQL running # on PGPORT specified make installcheck - To deploy on PostgreSQL VC++ builds you'll need to copy to PostgreSQL bin
bin: v8.dll, v8preparser.dll located in your mingw64/32 bin folder: libgcc_s_sjlj-1.dll, libstdc++-6.dll lib: plv8.dll share/extension -- the plv8 and plcoffee files from your mingw64 pg92 install (for some reason the install refused to install plcoffee.sql and plcoffee.control files files, so we had to manually copy those from the plv8 folder
Install and Test
In any 9.2 database:
CREATE EXTENSION plv8js;
CREATE EXTENSION plcoffee;
Coffee Test adapted from: http://umitanuki.hatenablog.com/entry/2012/05/11/025816
CREATE OR REPLACE FUNCTION fibonacci(n integer)
RETURNS integer LANGUAGE plcoffee IMMUTABLE STRICT
AS $function$
fibonacci = (x)->
return 0 if x == 0
return 1 if x == 1
return fibonacci(x-1) + fibonacci(x-2)
return fibonacci n
$function$;
SELECT i, fibonacci(i) As fib
FROM generate_series(5,30,3) As i;
i | fib
---+--------
5 | 5
8 | 21
11 | 89
14 | 377
17 | 1597
20 | 6765
23 | 28657
26 | 121393
29 | 514229
PLV8JS test from docs
CREATE FUNCTION to_jsontext(keys text[], vals text[]) RETURNS text AS
$$
var o = {};
for (var i = 0; i < keys.length; i++)
o[keys[i]] = vals[i];
return JSON.stringify(o);
$$
LANGUAGE plv8 IMMUTABLE STRICT;
SELECT to_jsontext(ARRAY['age', 'sex'], ARRAY['21', 'female']);
to_jsontext
-----------------------------
{"age":"21","sex":"female"}
PL Programming
PLV8JS and PLCoffee Part 1: Upserting Intermediate
Today's modern web application workflow in its simplest form looks something like this:
- Get dataset as JSON object usually using yet another JSON query object to pass the request using a javascript framework like JQuery/ExtJS/OpenLayers/Leaflet etc.
- Make changes to JSON dataset object and send back to the web server.
- On webserver unravel the JSON object and save to respective database tables. This part is really yucky as it often involves the web application server side language doing the unraveling and then yet another step of setting up stored procedures or other update logic to consume it.
We hate the way people build tiers for the same reason Cartman hates lines at the amusement park. Sure tiers are great for certain things like building connected microcosms, but most of the time they are overkill and if applied too early make your application needlessly complicated. In the end all we care about is data: serving data, analyzing data, getting good data and everything else is just peacock feathers.
The introduction of JSON type support in PostgreSQL 9.2 and languages PL/V8 (PL/Javascript) and its Pythoness-like twin PL/Coffee provides several options for bringing your data and application closer together since they have native support for JSON. In this first part we'll demonstrate one: An upsert stored procedure that takes a single JSON object instead of separate args and updates existing data and adds missing records. In later articles we'll show you the front end app and also add a sprinkle of PostGIS in there to demonstrate working with custom types.
Setting up the tables
We'll use this table and add more tables to this model in later articles:
CREATE TABLE inventory (prod_code varchar(20) primary key
, prod_name varchar(50)
, loc_id integer
, date_add timestamptz DEFAULT CURRENT_TIMESTAMP
, date_upd timestamptz DEFAULT CURRENT_TIMESTAMP
);
INSERT INTO inventory (prod_code, prod_name, loc_id)
VALUES ('BB1', 'Breadboard 174mm x 67mm', 1)
, ('SIR', 'Solder Iron', 2)
, ('TI_TMS5100', 'Texas Instruments TMS5100', 3);
The Upsert Stored procedure
PL/Javascript implementation
-- this will take a json dataset as input and do a data merge
CREATE OR REPLACE FUNCTION upsert_inventory(param_inv json) RETURNS
text AS $$
var o = JSON.parse(param_inv);
/** update plan **/
var uplan = plv8.prepare('UPDATE inventory SET prod_name = $1, loc_id = $2 WHERE prod_code = $3', ['text', 'int', 'text'] );
/** insert plan **/
var iplan = plv8.prepare('INSERT INTO inventory( prod_name, loc_id, prod_code) VALUES($1, $2, $3)', ['text', 'int', 'text'] );
var num_changed;
var num_ins = 0, num_upd = 0;
if (typeof o != 'object')
return NULL;
else {
for(var i=0; i<o.length; i++){
num_changed = uplan.execute([o[i].prod_name, o[i].loc_id, o[i].prod_code]);
num_upd += num_changed;
if (num_changed == 0){ /** we got no updates, so insert **/
num_changed = iplan.execute([o[i].prod_name, o[i].loc_id, o[i].prod_code]);
num_ins += num_changed;
}
}
}
iplan.free();
uplan.free();
return num_upd + ' record(s) updated and ' + num_ins + ' records inserted';
$$ LANGUAGE plv8 VOLATILE;
PL/CoffeeScript equivalent
CREATE OR REPLACE FUNCTION upsert_inventory(param_inv json) RETURNS
text AS $$
o = JSON.parse(param_inv)
# update plan
uplan = plv8.prepare("UPDATE inventory SET prod_name = $1, loc_id = $2 WHERE prod_code = $3", [ "text", "int", "text" ])
# insert plan
iplan = plv8.prepare("INSERT INTO inventory( prod_name, loc_id, prod_code) VALUES($1, $2, $3)", [ "text", "int", "text" ])
num_changed = undefined
num_ins = 0
num_upd = 0
unless typeof o is "object"
return NULL
else
i = 0
while i < o.length
num_changed = uplan.execute([ o[i].prod_name, o[i].loc_id, o[i].prod_code ])
num_upd += num_changed
if num_changed is 0 # we got no updates, so insert
num_changed = iplan.execute([ o[i].prod_name, o[i].loc_id, o[i].prod_code ])
num_ins += num_changed
i++
iplan.free()
uplan.free()
return num_upd + ' record(s) updated and ' + num_ins + ' records inserted'$$
LANGUAGE plcoffee VOLATILE;
Testing out the stored proc
-- this is to simulate data coming from jquery
-- or some other javascript client api
-- we aggregate all rows we want to change in an array
-- and then we convert the array of rows to
-- a single json object that will serve as our dataset
SELECT upsert_inventory(array_to_json(array_agg(inv)) )
FROM (SELECT replace(prod_name, 'Bread', 'Butter') As prod_name
, loc_id
, replace(prod_code, 'SIR', 'SIR2') as prod_code
FROM inventory ) As inv;
-- output of query --
2 record(s) updated and 1 records inserted
--Lets see what we have now --
SELECT prod_code, prod_name
FROM inventory ORDER BY prod_code;
prod_code | prod_name
------------+---------------------------
BB1 | Butterboard 174mm x 67mm
SIR | Solder Iron
SIR2 | Solder Iron
TI_TMS5100 | Texas Instruments TMS5100
PL Programming
PLV8JS and PLCoffee Part 2: JSON search requests Intermediate
PostgreSQL 9.2 beta3 got released this week and so we inch ever closer to final in another 2 months or so. One of the great new features is the built-in JSON type and companion PLV8/PLCoffee languages that allow for easy processing of JSON objects. One of the use cases we had in mind is to take as input a JSON search request that in turn returns a JSON dataset.
We'll use our table from PLV8 and PLCoffee Upserting. Keep in mind that in practice the json search request would be generated by a client side javascript API such as our favorite JQuery, but for quick prototyping, we'll generate the request in the database with some SQL.
If you are on windows and don't have plv8 available we have PostgreSQL 9.2 64-bit and 32-bit plv8/plcoffee experimental binaries and instructions. We haven't recompiled against 9.2beta3, but our existing binaries seem to work fine on our beta3 install.
Basic search stored function
This is a very basic search that assumes certain arguments of search term, page and offset are passed in the request.
-- PL/Javascript version CREATE OR REPLACE FUNCTION simple_search_inventory(param_search json) RETURNS json AS $$ o = JSON.parse(param_search); /** Take a json search request and output a json dataset **/ rs = plv8.execute("SELECT prod_code, prod_name " + " FROM inventory " + " WHERE prod_name ILIKE $1 LIMIT $2 OFFSET($3 - 1)*$2" , [o.prod_name_search, o.num_per_page, o.page_num]); return JSON.stringify(rs); $$ LANGUAGE plv8 VOLATILE;-- PL/Coffeescript version looks about the same except different comment tag and language specified CREATE OR REPLACE FUNCTION simple_search_inventory(param_search json) RETURNS json AS $$ o = JSON.parse(param_search) ## Take a json search request and output a json dataset rs = plv8.execute("SELECT prod_code, prod_name " + " FROM inventory " + " WHERE prod_name ILIKE $1 LIMIT $2 OFFSET ($3 - 1)*$2" , [o.prod_name_search, o.num_per_page, o.page_num]) return JSON.stringify(rs) $$ LANGUAGE plcoffee VOLATILE;To test the stored function, we'd write a query something like:
SELECT simple_search_inventory('{"prod_name_search":"%I%" , "num_per_page":2 , "page_num":1}'::json);Which would output something like this:
-- output --[{"prod_code":"SIR","prod_name":"Solder Iron"},{"prod_code":"TI_TMS5100","prod_name":"Texas Instruments TMS5100"}]
Using PostgreSQL Extensions
Foreign Data Wrap (FDW) Text Array, hstore, and Jagged Arrays
As we discussed in file_textarray_fdw Foreign Data Wrapper, Andrew Dunstan's text array foreign data wrapper works great for bringing in a delimited file and not having to worry about the column names until they are in. We had demonstrated one way to tag the field names to avoid having to keep track of index locations, by using hstore and the header column in conjunction. The problem with that is it doesn't work for jagged arrays. Jagged arrays are when not all rows have the same number of columns. I've jury rigged a small example to demonstrate the issue. Luckily with the power of PostgreSQL arrays you can usually get around this issue and still have nice names for your columns. We'll demonstrate that too.
Set up the foreign table
This particular file is noteworthy in 2 ways - it has line breaks in one of the columns which is a quoted column, thus the need to specify quote attribute, and not all rows have the same number of columns. You can download the sample file planet_aggregators.csv if you want to play along.
We set up the table with the following code:
CREATE SERVER file_tafdw_server FOREIGN DATA WRAPPER file_textarray_fdw;
CREATE USER MAPPING FOR public SERVER file_tafdw_server;
CREATE FOREIGN TABLE planet_aggregators( x text[] ) SERVER file_tafdw_server
OPTIONS (filename 'C:/fdw_data/planet_aggregators.csv', format 'csv', encoding 'latin1', delimiter E',', quote E'"');
Querying our table
Querying the table is easy. The standard way works and gives you a all rows.
SELECT * FROM planet_aggregators;Output is
x
----------------------------------------------------------------------------------------------------------------------
{Site,Description,"Home Page","Tag 1","Tag 2","Tag 3"}
{"Planet PostGIS","PostGIS - the best spatial database ever. +
Find out all that's happening in PostGIS land. ",http://planet.postgis.net,postgis,postgresql,gis}
{"Planet PostgreSQL","PostgreSQL - The most advanced open source databases",http://planet.postgresql.org,postgresql}
{"Planet OSGeo","Open Source Geospatial technologies",http://planet.osgeo.org,gis}
This doesn't work because in order to use the hstore function that matches headers with values, the header and value arrays must be the same bounds. Makes sense.
-- get error: array must have same bounds
WITH
cte As (SELECT hstore(headers.x, p.x) As kval
FROM (SELECT x
FROM planet_aggregators
LIMIT 1) As headers
CROSS JOIN planet_aggregators As p
)
SELECT kval->'Site' As site_name, kval->'Home Page' As web_site
FROM cte offset 1;
Fear not, the power of arrays will save us
WITH
cte As (SELECT hstore(headers.x[1:3], p.x[1:3]) As kval, p.x[4:6] As features
FROM (SELECT x
FROM staging.planet_aggregators
LIMIT 1) As headers
CROSS JOIN staging.planet_aggregators As p
)
SELECT kval->'Site' As site_name, kval->'Home Page' As web_site, features
FROM cte offset 1;
site_name | web_site | features
-------------------+------------------------------+--------------------------
Planet PostGIS | http://planet.postgis.net | {postgis,postgresql,gis}
Planet PostgreSQL | http://planet.postgresql.org | {postgresql}
Planet OSGeo | http://planet.osgeo.org | {gis}Using PostgreSQL Extensions
Building on MingW and deploying on VC compiled PostgreSQL Why and Why not
We are the windows package maintainers of PostGIS. We build these packages using MingW chain of tools. For other packages we fancy that do not come packaged with the windows VC++ builds, we also build these under mingw. We've described some of these already in File FDW family. For windows 32 builds we build with the commonly known MSys/Mingw32 chain (but an older version 1.0.11) because of issues we have building with the newer msys/mingw 32. For windows 64-bit installs, we build with the mingw-w64 chain and in fact we like the ming-w64 chain so much that we plan to migrate our Mingw32 to mingw64. We have PostgreSQL 9.2 and PostgreSQL 9.3 successfully installing under the mingw-w64 for windows 32 just fine (older PostgreSQL we experience a winsock.h something or other error which we are working on troubleshooting. For 64-bit we use ming-w64 for building extensions for PostgreSQL 9.0-9.2 and soon 9.3 with some minor issues. Some people have asked us, why put yourself thru this torture? Why not just build on MS VC++ for everything? Originally we had started on mingw because PostGIS needed a Unix like environment to compile and run thru the battery of tests. This is still the case, though PostGIS is planning a CMake move with help from Mateusz Lostkot which hopefuly will provide a better cross-platform experience and allows us to integrate pgRouting (which already is on CMake). Paul Ramsey rewrote many of the regression test scripts to be completely Perl based and not require sh. The other reality is we just prefer mingw and can't really stomach having to work with VC++. I'll describe why and why not build with mingw and deploy on VC++ compiled PostgreSQL.
Why?
MingW (at least for us is just more portable), perhaps it's because we are more familar with it. I have my workstation with a ming32/ming64 folder setup as we've described here. When I get a new workstation, I just copy the folders to the new pc and I'm ready to go. I'm builidng a buildbot for windows to auto build the PostGIS windows packages using jenkins and to get that compiling -- again I copied the ming32 and ming64 folders to the server and again it just works. The only trick launching from a batch script needed by the build bot, is I had to create a script that looks like this:
set WD=C:\ming64\msys\bin\ %WD%sh --login -i -c '"C:\path\to\myscript.sh"'Depending on whether we build for 32 or 64 I just toggle 32/64. The login seemed to be required to get libtools to work properly.
- VC++ we just don't care for. That is because we are web developers and only use VS for ASP.NET development. Having to then add in the VC++ is just another hassle.
- Each version of PostgreSQL (at least the EDB ones that most people use), are compiled with different versions of VC++ each requiring their own VC++ runtime distributed. So for example 9.1 was built with VS 2008. 9.2 will be built with VS 2010. PostGIS has a couple of dependency libraries which we build once for each PostGIS release and share across all the PostgreSQL versions and there is only one or two extra helper dlls to package for these (the stdc++ ones) which get copied in the PostgreSQL bin. If we were to build under VS we would have two choices: 1) build using the VC++ EDB builds with, yet another clutter of our workspace or 2) package whatever runtime libraries we are using which would make our setup exe much more complicated.
- Many of the extensions people build for PostgreSQL, PostGIS included, assume a pgxs capable install. VC builds don't support pgxs. So if you are trying to compile an extension built by a Unix/Mac User on windows with VC++, you are screwed or have to rollup your sleeves to figure out how to hack their build script to work for you. Our VC++ skills are nil. The story is even worse for 64-bit PostgreSQL. Under mingw 32/64, it generally just works even for building 64-bit libraries. I like being special but I don't like being that special. I want to be able to compile things much the same way as anyone else working on the projects I work with. I don't want to ask other developers to make special concessions to get it to work for me and continually baby sit these changes. As it stands windows VC++ is probably the only environment that requires a non-Unix like environment to work. Sure others have idiosyncracies, but they don't require you to rearchitect your whole build system to work for them.
- I find it a lot easier to get a Unix developer to stab themselves with a pitch fork than to get a Windows developer to lift a finger for anything that is not a pure windows project. I'll explain in the why not section. I think part of the reason for that is that it's more common to find Unix developers that started life as windows developers. So they are familiar with both environments and the underlying codebase. The other reason is a lot of large corporations still run on windows and it makes good business sense to support people who have money assuming you can get them to shoot some of that your way.
Why Not?
- Sadly, some extensions built under MingW will not work under VC++. One example is PL/R. When PostgreSQL 8.3 came out and the packaged PostgreSQL windows installers switched to VC++ builds from MingW, it left many PL/R windows users very unhappy. For some reason the PL/R windows users were compiling under MingW wouldn't load on these new VC++ creatures. After much crying from windows folks and several of us trying to figure out what was wrong, we all concluded it was the VC++ switch. Joe Conway stepped up to the plate and proverbially stabbed himself with a pitchfork to revise his build scripts to work on VC++. This meant for him setting up a windows VM VC++ Express, running into unchartered scary territory I imagine for him. Andrew Dunstan is another fine example. Andrew, BTW your changes to FDW Fixed Length still don't work for me. I'm going to verify to make sure it's not something wrong with my environment before I bug you.
- Mixing build systems is really not supported and some are shocked it works. If you ask some PostgreSQL key contributors, their jaws sometimes drop when you tell them what you are doing. Enough said.
- Memory issues even for PostGIS the 64-bit mingW compiled works fine against a mingW PostgreSQL but crashes on the input KML/GM tests when run from sh. The odd thing is it works fine when you manually run the test from PostgreSQL VC++. So it's hard to tell where this issue is coming from and if it would exist in a pure VC++ environment. I suspect it would.
General Tips for using MingW for compiling
We build on windows, so all the cross-compiling features of MingW are a bit lost on us. I don't have much of a clue how it works on Unix systems, though Andrew described a bit how to get going with it on Unix in Cross-compiling PostgreSQL for windows
Overwrite your
PATHvariable on your scripts. Most issues we've had with compiling not working the same on one pc from another is all the path junk brought in from windows from other installs you've got going. Suddenly your code has dependencies on dlls distributed by Tortoise etc. and you're hunting around what stray cat came thru.For example the header of our sh scripts looks something like this:
export PROJECTS=/c/ming64/projects export PATH=".:/usr/local/bin:/mingw/bin:/bin:/c/Windows/system32:/c/Windows" export PATH=${PROJECTS}/pgx64/pg91/bin/:$PATHThis is especially true when building for 64-bit.
Don't install non-standard dependencies in the default location. Just add them to your path variable as needed. Case in point, each version of PostGIS uses a different version of GEOS and sometimes we have to test many. We also build for many versions of PostgreSQL. Keeping these separate helps immensely.
- Use dependency walker to check what dlls you are missing. Most often, a mingw library doesn't load on VC++ build because you are missing libstdc++ or some other c helper library. Often times you need others (PostGIS has several like libgdal, geos, proj, libxml-xml2 etc.). Dependency Walker will help you sniff out these issues.
Application Development
PLV8JS and PLCoffee Part 2B: PHP JQuery App Intermediate
In our last article, PL/V8JS and PL/Coffee JSON search requests we demonstrated how to create a PostgreSQL PL/Javascript stored function that takes as input, a json wrapped search request. We generated the search request using PostgreSQL. As mentioned, in practice, the json search request would be generated by a client side javascript API such as JQuery. This time we'll put our stored function to use in a real web app built using PHP and JQuery. The PHP part is fairly minimalistic just involving a call to the database and return a single row back. Normally we use a database abstraction layer such as ADODB or PearDB, but this is so simple that we are just going to use the raw PHP PostgreSQL connection library directly. This example requires PHP 5.1+ since it uses the pg_query_param function introduced in PHP 5.1. Most of the work is happening in the JQuery client side tier and the database part we already saw. That said the PHP part is fairly trivial to swap out with something like ASP.NET and most other web server side languages.
The PHP script
The PHP script is shown below. To keep it short, we just put the connection string right in the php script and did away with all the try / catch logic we usually put in.
<?php
$db = pg_pconnect("host=localhost port=5432 dbname=testplv8 user=demouser password=foofoo");
if (isset($_POST['json_search'])){
/** parameterized sql statement that takes a json object as input **/
$sql = 'SELECT simple_search_inventory($1::json);';
/** Execute the statement passing the json object in Post **/
$result = pg_query_params($db, $sql, array($_POST['json_search']) );
$row = pg_fetch_row($result);
pg_free_result($result);
pg_close($db);
/**output json result **/
echo $row[0];
}
else {
echo "no request made";
}
pg_close($db);?>
JQuery Client-side Code
For the client side JQuery side, we did away with all that css fanciness to make this short. Also not much in the way of error handlers. The searchInventory function that gets triggered on click of the search button does most of the work by packaging the form search variables into a json request, handing it off to the php script, and then processing the json dataset that comes back. A good portion of the code uses JQuery idioms and functions.
<html>
<head><title>Inventory Search App</title>
<script type="text/javascript" src="http://code.jquery.com/jquery-1.7.2.min.js"></script>
<script type="text/javascript">
/** this is boiler plate code from:
http://jsfiddle.net/sxGtM/3/ converts array of form elements to associative array **/
$.fn.serializeObject = function()
{
var o = {};
var a = this.serializeArray();
$.each(a, function() {
if (o[this.name] !== undefined) {
if (!o[this.name].push) {
o[this.name] = [o[this.name]];
}
o[this.name].push(this.value || '');
} else {
o[this.name] = this.value || '';
}
});
return o;
};
function searchInventory() {
frmdata = $('#frmSearch').serializeObject();
/** remove all rows after header and template row
to prevent appending of results from prior searches **/
$('#tblresults').find("tr:gt(1)").remove();
/** post JSON formatted search input and get back JSON dataset **/
$.post('inventory_app.php', {'json_search': JSON.stringify(frmdata, null, '\t')}
,function(data) {
var rs = $.parseJSON(data);
$('#spandetail').html('There are ' + rs.length + ' item(s).')
/** Look through rows of dataset **/
$.each(rs, function() {
var result = $('#template_row').html();
/** Look through columns of row **/
$.each(this, function(cname,val) {
/** hack to html encode value **/
htmlval = $('<div />').text(val).html();
/** replace :column_name: in template with column value **/
result = result.replace(':' + cname + ':', htmlval);
});
$("#tblresults").append('<tr>' + result + '</tr>');
});
/** hide our template row **/
$('#template_row').hide();
/**show our search results **/
$('#tblresults').show();
}
);
}
</script>
</head>
<body>
<form id="frmSearch">
<b>Product Name:</b> <input type="text" id="prod_name_search" name="prod_name_search" style="width:100px" />
<b># per page</b> <input type="text" name="num_per_page" value="100" style='width:30px' readonly />
Page: <input type="text" name="page_num" value="1" style='width:30px' readonly />
<input type="button" name="cmdSearch" value="search" onclick="searchInventory()" />
</form>
<span id='spandetail'></span>
<table id="tblresults" style='display:none'>
<tr><th>Code</th><th>Product Name</th></tr>
<tr id='template_row'><td>:prod_code:</td><td>:prod_name:</td></tr>
</table>
</body>
</html>
The output screen looks like this:

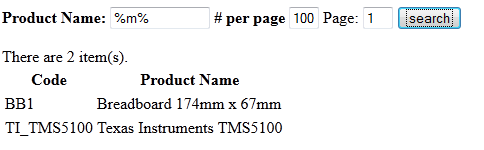
When you do a search and click the search button you get this:
Application Development
Creating GeoJSON Feature Collections with JSON and PostGIS functions
If you do a lot of web-based GIS applications, a common desire is to allow a user to draw out an area on the map and then do searches against that area and return back a FeatureCollection where each feature is composed of a geometry and attributes about that feature. In the past the format was GML or KML, but the world seems to be moving to prefer JSON/GeoJSON. Normally you'd throw a mapping server that talks Web Feature Service , do more or less with a webscripting glue, or use a Webservice such as CartoDb that lets you pass along raw SQL.
In this article we'll demonstrate how to build GeoJSON feature collections that can be consumed by web mapping apps. using the built in JSON functions in PostgreSQL 9.2 and some PostGIS hugging. Even if you don't use PostGIS, we hope you'll come away with some techniques for working with PostgreSQL extended types and also how to morph relational data into JSON buckets.
Outputting GeoJSON Feature Collections
We want the result of all our searches to output as GeoJSON feature collections which look something like the below (partially clip from GeoJSON spec
{ "type": "FeatureCollection",
"features": [
{ "type": "Feature",
"geometry": {"type": "Point", "coordinates": [102.0, 0.5]},
"properties": {"prop0": "value0"}
},
{ "type": "Feature",
"geometry": {
"type": "LineString",
"coordinates": [
[102.0, 0.0], [103.0, 1.0], [104.0, 0.0], [105.0, 1.0]
]
},
"properties": {
"prop0": "value0",
"prop1": 0.0
}
}
]
}
As you can see it's not the nice flat tabular looking thing we relational database folks have grown to love. It's got a few curves here and there and the geometry column is output separate from the other fun loving attributes. This is different from what we showed in PostgreSQL 9.2 Native JSON type support.
While you need PLV8JS to consume something like this, you can generate something like this with barebones PostgreSQL JSON support. So how do you do that?
Setup our test data
We'll test using this table:
CREATE TABLE locations(loc_id integer primary key
, loc_name varchar(70), geog geography(POINT) );
INSERT INTO locations(loc_id, loc_name, geog)
VALUES (1, 'Waltham, MA', ST_GeogFromText('POINT(42.40047 -71.2577)') )
, (2, 'Manchester, NH', ST_GeogFromText('POINT(42.99019 -71.46259)') )
, (3, 'TI Blvd, TX', ST_GeogFromText('POINT(-96.75724 32.90977)') );
Query to output as FeatureCollection
To output as a feature collection, we can do this:
SELECT row_to_json(fc)
FROM ( SELECT 'FeatureCollection' As type, array_to_json(array_agg(f)) As features
FROM (SELECT 'Feature' As type
, ST_AsGeoJSON(lg.geog)::json As geometry
, row_to_json(lp) As properties
FROM locations As lg
INNER JOIN (SELECT loc_id, loc_name FROM locations) As lp
ON lg.loc_id = lp.loc_id ) As f ) As fc;
or avoiding a self-join by doing this
SELECT row_to_json(fc)
FROM ( SELECT 'FeatureCollection' As type, array_to_json(array_agg(f)) As features
FROM (SELECT 'Feature' As type
, ST_AsGeoJSON(lg.geog)::json As geometry
, row_to_json((SELECT l FROM (SELECT loc_id, loc_name) As l
)) As properties
FROM locations As lg ) As f ) As fc;
Both above queries output the below, which we've reformatted to fit better on the page
{"type":"FeatureCollection",
"features":[
{"type":"Feature","geometry":{"type":"Point","coordinates":[42.400469999999999,-71.2577]},
"properties":{"loc_id":1,"loc_name":"Waltham, MA"}},
{"type":"Feature","geometry":{"type":"Point","coordinates":[42.990189999999998,-71.462590000000006]},
"properties":{"loc_id":2,"loc_name":"Manchester, NH"}},
{"type":"Feature","geometry":{"type":"Point","coordinates":[-96.757239999999996,32.909770000000002]},
"properties":{"loc_id":3,"loc_name":"TI Blvd, TX"}}
]
}
Now you may be wondering why we need a self join or nested subselect. Although PostgreSQL 9.2 is smarter now about inferring column names in a subquery, thanks to Andrew Dunstan, Tom Lane, and others, it still is not capable of allowing you to define a row object with nice column names without casting to a defined type. So if you did the shorter:
SELECT row_to_json(fc)
FROM ( SELECT 'FeatureCollection' As type, array_to_json(array_agg(f)) As features
FROM (SELECT 'Feature' As type
, ST_AsGeoJSON(lg.geog)::json As geometry
, row_to_json((loc_id, loc_name)) As properties
FROM locations As lg ) As f ) As fc;
You get stuck with f1,f2...fn for column names as shown here:
{"type":"FeatureCollection",
"features":[
{"type":"Feature","geometry":{"type":"Point","coordinates":[42.400469999999999,-71.2577]},
"properties":{"f1":1,"f2":"Waltham, MA"}},
{"type":"Feature","geometry":{"type":"Point","coordinates":[42.990189999999998,-71.462590000000006]},
"properties":{"f1":2,"f2":"Manchester, NH"}},
{"type":"Feature","geometry":{"type":"Point","coordinates":[-96.757239999999996,32.909770000000002]},
"properties":{"f1":3,"f2":"TI Blvd, TX"}}]
}