Table Of Contents
PostgreSQL 9.2 Native JSON type support
PostgreSQL 9.2: Preserving column names of subqueries
What's new and upcoming in PostgreSQL
PostgreSQL 9.2 pg_dump enhancements
One of the things I'm excited about in PostgreSQL 9.2 are the new pg_dump section - pre-data, data, and post-data options and the exclude-table-data option. Andrew Dunstan blogged about this briefly in pg_dump exclude table data. What is also nice is that pgAdmin III 1.16 supports the section option via the graphical interface 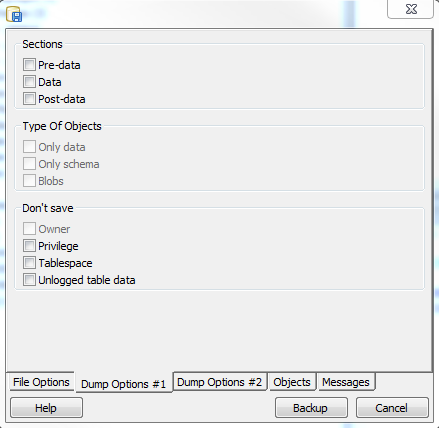 . I was a bit disappointed not to find the exclude-table-data option in pgAdmin III interface though.
The other nice thing about this feature is that you can use the PostgreSQL 9.2 dump even against a 9.1 or lower db and achieve the same benefit.
. I was a bit disappointed not to find the exclude-table-data option in pgAdmin III interface though.
The other nice thing about this feature is that you can use the PostgreSQL 9.2 dump even against a 9.1 or lower db and achieve the same benefit.
The 9.2 pg_restore has similar functionality for restoring specific sections of a backup too.
So what is all this section stuff for. Well it comes in particularly handy for upgrade scripts. I'll first explain what the sections mean and a concrete example of why you want this.
- pre-data - this would be the table structures, functions etc without the constraints such as check and primary key and indexes.
- data -- it's uhm the data
post-data - This is all constraints, primary keys, indexes etc.
Use case: sections - convert your play database to a template
Imagine you've been developing your app and have lots of test data, eventually you'll want to deploy your database as a template or a set of scripts. You certainly don't want to include your junk data, so you want your backup to include -- Pre-data and Post-data. Since it will be so light and fluffy, you might as well just output it as plain text so you'd run a command something like
pg_dump --host localhost --port 5432 --format plain --section pre-data --section post-data --file myscript.sql mydb
Use case for exclude-table-data
exclude table data option is most useful for as Andrew mentioned, not wasting your backup with huge static data, and yet still being able to backup the structure. It also comes in useful for deploying stuff too like the previous example.
Imagine you are developing an app say an app for managing a store, and you want to deploy data as well like states, taxes etc, but not your junk orders, however you want table structure for your orders etc to be part of your script. One way is to set aside a schema for store data and another for your other data you will package. The schema store would contain all customer data. You would create a script something like this which would have the effect of including all your other data but only dumping out the table structures in your store schema (and not the data).
pg_dump --host localhost --port 5432 --format plain --exclude-table-data=store.* --file myscript.sql mydb
Though I didn't demonstrate it, these commands all work with custom and tar backup format as well.
What's new and upcoming in PostgreSQL
PostgreSQL 9.2 Native JSON type support
One new welcome feature in PostgreSQL 9.2 is the native json support and companion row_as_json and array_as_json functions. PostGIS also has a json function for outputting geographies and geometries in GeoJSON format which is almost a standard in web mapping.
Here is an example of how you'd use the new feature - create our test table
CREATE TABLE test(gid serial PRIMARY KEY, title text, geog geography(Point, 4326));
INSERT INTO test(title, geog)
VALUES('a'
, ST_GeogFromText('POINT(-71.057811 42.358274)'));
INSERT INTO test(title, geog)
VALUES('b'
, ST_GeogFromText('POINT(42.358274 -71.057811 )'));
Now with a command like this we can output all data as a single json object.
SELECT array_to_json(array_agg(t))
FROM test As t;But there is a tincy little problem. Our geog outputs don't look anything like GeoJSON format. Our output looks like this:
[{"gid":1,"title":"a","geog":"0101000020E61000005796E82CB3C3
51C0E98024ECDB2D4540"}
,{"gid":2,"title":"b","geog":"0
101000020E6100000E98024ECDB2D45405796E82CB3C351C0"}]
To follow the GeoJSON standard, our geography object should output like this:
"geog":{"type":"Point","coordinates":[-71.057811000000001,42.358274000000002]}
We were hoping it would be a simple matter of defining a cast for geometry and geography something like this:
CREATE OR REPLACE FUNCTION json(geog geography)
RETURNS json AS
$$ SELECT _ST_AsGeoJSON(1, $1, 15, 0)::json; $$
LANGUAGE sql IMMUTABLE STRICT;
CREATE CAST (geography AS json)
WITH FUNCTION json(geography)
AS IMPLICIT;And with the above CAST, array_to_json would be Clearly I'm missing something here. I have to apply this work-around:
SELECT array_to_json(array_agg(t)) As my_places
FROM (SELECT gid, title, geog::json As geog FROM test) As t; [{"gid":1,"title":"a"
,"geog":{"type":"Point"
,"coordinates":[-71.057811000000001,42.358274000000002]}}
,{"gid":2,"title":"b"
,"geog":{"type":"Point"
,"coordinates":[42.358274000000002,-71.057811000000001]}}]
Which ain't bad and much better than before, but is not quite as nice as being able to just use aray_to_json without care of types of columns and have array_to_json function automatically use a json CAST if a type provides a custom json CAST. I have this ticketed in PostGIS 2.1 as a nice feature to have.
What's new and upcoming in PostgreSQL
PostgreSQL 9.2: Preserving column names of subqueries
There is another new feature in 9.2 that doesn't get much press, and probably because it's hard to explain. It is a pretty useful feature if you are working with the new json type or the existing hstore type. In prior versions if you used a subquery and converted the rows to hstore or json the column names were not preserved. Andrew mentioned a back-port path for this issue in Upgradeable JSON. We described a workaround for this issue in Mail merging using hstore. The workaround for including PostGIS geometry in json record output as described in Native JSON type support wouldn't work as nicely without this enhancement. Here is an example to demonstrate.
CREATE EXTENSION hstore;
CREATE TABLE clients(client_id varchar(5) PRIMARY KEY, contact_name varchar(100), business varchar(100));
INSERT INTO clients(client_id, contact_name, business)
VALUES ('DCH', 'John Dewey', 'Dewey, Cheetham, and Howe'),
('IYS', 'Spencer Tracey', 'Investigators at Your Service'),
('ABC', 'Abby Back', 'It is all about ABC');
SELECT client_id, hstore(c) As data
FROM (SELECT client_id, contact_name
FROM clients) As c;
If you were running the above query in 9.1 or lower, you'd get this which as you can see is not ideal:
--9.1 behavior client_id | data -----------+------------------------------------- DCH | "f1"=>"DCH", "f2"=>"John Dewey" IYS | "f1"=>"IYS", "f2"=>"Spencer Tracey" ABC | "f1"=>"ABC", "f2"=>"Abby Back"
If you run the same exact query in 9.2, you get this much nicer output
--9.2 behavior client_id | data ----------+------------------------------------------------------ DCH | "client_id"=>"DCH", "contact_name"=>"John Dewey" IYS | "client_id"=>"IYS", "contact_name"=>"Spencer Tracey" ABC | "client_id"=>"ABC", "contact_name"=>"Abby Back"
PostgreSQL Q & A
Finding contiguous primary keys Intermediate
I recently had the need to figure out which ranges of my keys were contiguously numbered. The related exercise is finding gaps in data as well.
Reasons might be because you need to determine what data did not get copied or what records got deleted. There are lots of ways of accomplishing this, but this is the
first that came to mind. This approach uses window aggregates lead function and common table expressions, so requires PostgreSQL 8.4+
Create dummy data with gaps to test with
-- our test table
-- this creates gaps after 199 records
CREATE TABLE s(n integer);
INSERT INTO s(n)
SELECT n
FROM generate_series(1,1000) As n
WHERE n % 200 != 0;
Now the solution
WITH
-- get start ranges (numbers that don't have a matching next + 1)
n1 AS (SELECT n AS start_n
FROM s
EXCEPT
SELECT n + 1 AS start_n
FROM s),
-- for each start range find the next start range
n2 AS (SELECT n1.start_n
, lead(start_n) OVER (ORDER BY start_n) As next_set_n
FROM n1
GROUP BY n1.start_n)
-- determine end range for each start
-- end range is the last number that is before start of next range
SELECT start_n, MAX(COALESCE(s.n,start_n)) As end_n
FROM n2 LEFT JOIN s ON( s.n >= n2.start_n AND (s.n < n2.next_set_n or n2.next_set_n IS NULL))
GROUP BY start_n, next_set_n
ORDER BY start_n;
The result of the above query looks like:
start_n | end_n
----------+-------
1 | 199
201 | 399
401 | 599
601 | 799
801 | 999Using PostgreSQL Extensions
File FDW Family: Part 1 file_fdw
Last time we demonstrated how to use the ODBC Foreign Data wrapper, this time we'll continue our journey into Foreign Data Wrapper land by demonstrating what I'll call the File FDW family of Foreign Data Wrappers. There is one that usually comes packaged with PostgreSQL 9.1 which is called fdw_file but there are two other experimental ones I find very useful which are developed by Andrew Dunstan both of which Andrew demoed in PostgreSQL Foreign Data Wrappers and talked about a little bit Text files from a remote source. As people who have to deal with text data files day in and out, especially ones from mainframes, these satisfy a certain itch.
- file_fdw - for querying delimited text files.
- file_fixed_length_fdw - this one deals with fixed length data. We discussed methods of importing fixed length data in Import Fixed width data. This is yet another approach but has the benefit that you can also use it to import just a subset of a file.
- file_text_array_fdw - this one queries a delimited file as if each delimiete row was a text array. It is ideal for those less than perfect moments when someone gives you a file with a 1000 columns and you don't have patience to look at what the hell those columns mean just yet.
In this article, we'll just cover the file_fdw one, but will follow up in subsequent articles, demonstrating the array and fixed length record ones.
Before we begin, We'll create a staging schema to throw all our foreign data tables.
CREATE SCHEMA staging;We'll also create a folder on on the root of our postgres server called fdw_data where we will house all the flat files. Make sure the postgres service account has access to it.
Using file_fdw
We'll start with the
Setting up Foreign Data Table using the file_fdw driver
- Install the extension with the SQL statement
CREATE EXTENSION file_fdw; - Create a Foreign server This is pretty much a formality for file_fdw since hte file always is on the local postgresql server.
CREATE SERVER file_fdw_server FOREIGN DATA WRAPPER file_fdw; - Create a Foreign Table
For this exercise, we'll pull a tab delimited data file from FAA Aircraft Reference called aircraft.txt and save to /fdw_data folder. The file layout is found at AircraftFileLayout.txt
Note that the aircraft.txt has a header row. We'll save this to our fdw_data folder
CREATE FOREIGN TABLE staging.aircraft ( Model Char (12), Last_Change_Date VarChar(10), Region VarChar(2), Make VarChar(6), Aircraft_Group VarChar(6), Regis_Code VarChar(7), Design_Character VarChar(3), No_Engines VarChar(11), Type_Engine VarChar(2), Type_Landing_Gear VarChar(2), TC_Data_Sheet_Number VarChar(8), TC_Model VarChar(20) ) SERVER file_fdw_server OPTIONS (format 'csv',header 'true' , filename '/fdw_data/aircraft.txt', delimiter E'\t', null '');You can change the location of a file as well. For example, the query above will not work if you are on windows. You'll need to specify the drive letter as well. You can do this:
ALTER FOREIGN TABLE staging.aircraft OPTIONS ( SET filename 'C:/fdw_data/aircraft.txt' );
Now to query our table, we simply do this:
SELECT model, region, make, last_change_date
FROM staging.aircraft
WHERE make LIKE 'BEECH%'
ORDER BY last_change_date DESC LIMIT 5;
model | region | make | last_change_date --------------+--------+--------+------------------ B200CT | CE | BEECH | 12/18/2001 3000 | CE | BEECH | 12/17/2001 B300C | CE | BEECH | 10/11/2001 C12C | CE | BEECH | 10/11/2001 65A901 | CE | BEECH | 10/11/2001
Notice in the above definition that the Last_change_date field is set to varchar(10), but when we look at the data, it's in American date format and sorting is not using date sorting so records get sorted by month first. To force date sorting, we can make this change
We could do this:ALTER FOREIGN TABLE staging.aircraft ALTER COLUMN last_change_date type date;
And that works great if you are in the US since the default DateStyle is MDY and rerunning the query gives:
model | region | make | last_change_date -------------+--------+--------+------------------ U21A | CE | BEECH | 2004-01-28 B200CT | CE | BEECH | 2001-12-18 3000 | CE | BEECH | 2001-12-17 65A901 | CE | BEECH | 2001-10-11 C12C | CE | BEECH | 2001-10-11
However if your DateStyle is 'DMY' as it is in Europe and other places, you'll get an error when you go to query the data. We couldn't find a way to force the DateStyle property of a foreign table column aside from doing this:
set DateStyle='MDY'
before running a query on the table
Using PostgreSQL Extensions
File FDW Family: Part 2 file_textarray_fdw Foreign Data Wrapper
Last time we demonstrated how to query delimited text files using the fdw_file that comes packaged with PostgreSQL 9.1+, this time we'll continue our journey into Flat file querying Foreign Data Wrapper using an experimental foreign data wrapper designed for also querying delimited data, but outputting it as a single column text array table. This one is called file_textarray_fdw and developed by Andrew Dunstan. It's useful if you are dealing with for example jagged files, where not all columns are not properly filled in for each record or there are just a ton of columns you don't want to bother itemizing before you bring in. The benefit is you can still query and decide how you want to break it apart. You can grab the source code from file_text_array_fdw source code. If you are on windows, we have compiled binaries in our Bag o' FDWs for both PostgreSQL 9.1 32-bit FDW for Windows bag and PostgreSQL 9.1 64-bit FDW for Windows bag that should work fine with the EDB installed windows binaries. For other systems, the compile is fairly easy if you have the postgresql development libraries installed.
We'll be using the same database schema and system file folder to house things as we did in our prior article.
Setting up Foreign Data Table using the file_textarray_fdw driver
- Install the extension binaries - for windows users, just copy the files in the same named folders of your PostgreSQL install. On other systems, you'll need to compile and it should automatically install the files for you using
make installor you can do just amakeand copy the .sql and .control files into the PostgreSQL share/extensions folder, and the .so files into your PostgreSQL lib folder. Keep in mind, you need PostgreSQL 9.1 or above. - Install the extension in your database of choice with the SQL statement
CREATE EXTENSION file_textarray_fdw; - Create a Foreign server This is pretty much a formality for file_textarray_fdw as well since file always is on the local postgresql server.
CREATE SERVER file_tafdw_server FOREIGN DATA WRAPPER file_textarray_fdw; - Create user mapping -
This is often necessary to do for most foreign data wrappers, though for some reason we were able to skip this step with the file_fdw one. We need to create a foreign data mapping user to a database user. We don't want to itemize what users can access our data source, so'll create just a group mapping for all users using the group role
publicwhich all our users of our database are members of.CREATE USER MAPPING FOR public SERVER file_tafdw_server; - Download the data
For this exercise, we'll use the 2010 Gazetteer natial place which is tab-delimited and can be downloaded from census 2010 places data and more specifically the Gaz_places_national.txt which we will save in our local server fdw_data folder.
- Create a Foreign Table - Now we are ready for the fun part, creating our table.
CREATE FOREIGN TABLE staging.places2010( x text[] ) SERVER file_tafdw_server OPTIONS (filename '/fdw_data/Gaz_places_national.txt', encoding 'latin1', delimiter E'\t');You can change the location of a file as well. For example, the query above will not work if you are on windows. You'll need to specify the drive letter as well. You can do this:
ALTER FOREIGN TABLE staging.places2010 OPTIONS ( SET filename 'C:/fdw_data/Gaz_places_national.txt' );
Now to query our table, we do this:
SELECT x[1] As state, x[4] As place
FROM staging.places2010
WHERE x[1] = 'STUSPS'
OR (x[1] IN('RI', 'DC') AND x[4] ILIKE 'wa%');
This will give both the header column and all data for Rhode Island and DC fitting our criterion.
state | place --------+------------------------- STUSPS | NAME DC | Washington city RI | Wakefield-Peacedale CDP RI | Warwick city RI | Watch Hill CDP
Note I kept the header, this allows for easily flipping to a more friendly hstore structure. For this next example, you'll need hstore installed and if you don't have it install it with:
CREATE EXTENSION hstore;
We'll use a common table expression, but you can just as easily dump the data into a table of your choosing.
WITH
cte As (SELECT hstore(headers.x, p.x) As kval
FROM (SELECT x
FROM staging.places2010
WHERE x[1] = 'STUSPS') As headers
CROSS JOIN staging.places2010 As p
WHERE (p.x[1] IN('RI', 'DC') AND p.x[4] ILIKE 'wa%') )
SELECT kval->'STUSPS' As state, kval->'NAME' As name, kval->'GEOID' As geoid
FROM cte
ORDER BY kval->'NAME';
state | name | geoid -------+-------------------------+--------- RI | Wakefield-Peacedale CDP | 4473130 RI | Warwick city | 4474300 DC | Washington city | 1150000 RI | Watch Hill CDP | 4475200
Possible Options for the file_textarray_fdw
Every FDW has its own set of options, which makes sense since FDWs are so varied in purpose. I only used a couple of options in this tutorial for the foreign table, but here is a more exhaustive list of what's available for file_textarray_fdw
- filename - the file path of the file in the table
- encoding - the character encoding of the file. In this example, the file will not work with my default db encoding of UTF-8. If you get a byte sequence invalid error when querying your table, you need to specify the encoding since it means the encoding of the file is not the same as your db
- format
- delimiter - this is the character delimiter for the columns, the default is the tab characer E'\t', so we didn't really need to specify it, but if you are using something like '|' or comma or some other separator, you'll need it.
- quote - same as copy mode - what is the character used in quoting text. Our data wasn't quoted so we didn't need this.
- format -
- header - this should be set to 'true' or 'false'. Works the same as psql copy. It will strip the first row if set to true. In this case we wanted to keep the header so we could easily flip to hstore.
- null -- what to consider as the null character.
- escape -- character used for escaping text, e.g. if you had a quote or delimeter in text, what would escape it so you know it should be included. We didn't need to worry since no special characters were used such as tab.