Table Of Contents
From the Editors
Back from DDOS Attack
As many may have noticed, PostgresOnline.com has been down for the past week or so and probably is still not reachable from many parts of the world since our DNS server was also taken down as a result of a Distributed Denial of Service (DDOS) attack instigated by an Activision Call of Duty Game exploit that turned thousands of Call of Duty game servers into Zombies launching an attack on us.
We have a small confession to make. One of the businesses we co-own is an e-Commerce site that sells condoms. You never know how people will react when you say that in mixed company so we only mention it in closer company. Some people are glad we are in a business protecting against venereal diseases or unwanted pregnancies and some feel strongly we are violating a mother nature creed of conduct. WowCondoms was the site that was under attack on a UDP port and we are not sure if it was a malicious intent or not since the root instigator has not been found yet. The attack was higher up from our servers so it knocked our ISP who in turn blamed us for their outage. We never saw the traffic.
The tragic thing is that it can happen to any site and does all the time. It really hit home when it happened to us.
Details of our fight are described here: WowCondoms plugs hole in Activision's Call of Duty Game Servers
PostgreSQL Q & A
Table Inheritance and the tableoid Beginner
If I could name a number one feature I love most about PostgreSQL, it's the table inheritance feature which we described in How to Inherit and Uninherit. A lot of people use it for table partitioning using CONSTRAINT EXCLUSION. Aside from that, in combination with PostgreSQL schema search_path (customizable by user and/or database) it makes for a very flexible abstraction tool. For example, for many of our web apps that service many departments where each department/client wants to keep a high level of autonomy, we have a schema set aside for each that inherits from a master template schema. Each department site uses a different set of accounts with the primary schema being that of the department/client so that they are hitting their own tables.
Inheritance allows us to keep data separate,do roll-up reports if we need to, use the same application front-end, and yet allows us the ability to add new columns in just one place (the master template schema). It is more flexible than other approaches because for example we may have a city organization that need to share tables, like for example a system loaded list of funding source shared across the agency. We can set aside these shared tables in a separate schema visible to all or have some have their own copy they can change if they don't want to use the shared one.
Every once in a while, we find ourselves needing to query the whole hierarchy and needing to know which table the results of the query are coming from. To help solve that issue, we employ the use of the system column tableoid which all user tables have. The tableoid is the the object id of a table. PostgreSQL has many system columns that you have to explicitly select and can't be accessed with a SELECT * with the tableoid being one of them. These are: tableoid, cmax,cmin, xmin,xmax,ctid which are all described in System Columns. The PostgreSQL docs on inheritance have examples of using it, but we thought it worthwile to repeat the exercise since it's not that common knowledge and is unique enough feature of PostgreSQL that others coming from other relational databases, may miss the treat. I've often demonstrated it to non-PostgreSQL users who use for example SQL Server or MySQL, and they literally fall out of their chair when I show the feature to them and its endless possibilities.
Creating our very healthy environment
For this exercise, we'll use the example from How to Inherit and Uninherit, note that later versions of PgAdmin III, do have this built into the interface, so the short-comings we described in the article don't exist for PgAdmin III 1.10 and above.
First we create the tables and populate them like so:
CREATE SCHEMA micromanagers;
CREATE TABLE micromanagers.timesheet
(
ts_date date NOT NULL,
ts_hours numeric(5,2) NOT NULL DEFAULT 0,
ts_employeename character varying(50) NOT NULL,
CONSTRAINT pk_timesheet PRIMARY KEY (ts_date, ts_employeename)
);
CREATE SCHEMA icecreammakers;
CREATE TABLE icecreammakers.timesheet
( CONSTRAINT pk_timesheet PRIMARY KEY (ts_date, ts_employeename)
) INHERITS (micromanagers.timesheet);
CREATE SCHEMA whitecollar;
CREATE TABLE whitecollar.timesheet
( CONSTRAINT pk_timesheet PRIMARY KEY (ts_date, ts_employeename)
) INHERITS (micromanagers.timesheet);
set search_path=icecreammakers;
INSERT INTO timesheet(ts_date,ts_hours,ts_employeename)
VALUES('2012-01-16', 5, 'rrunner');
set search_path=micromanagers;
INSERT INTO timesheet(ts_date,ts_hours,ts_employeename)
VALUES('2012-01-16', 20, 'wecoyote');
set search_path=whitecollar;
INSERT INTO timesheet(ts_date,ts_hours,ts_employeename)
VALUES('2012-01-16', 7, 'dduck');
Which group is Road Runner in?
Wile E. Coyote is doing his rounds and is particularly interested in the whereabouts of Road Runner who seems to jump around from department to department. He wants to know where Road Runner is hiding out today.
-- Check - let us be a Wiley --
set search_path=micromanagers;
SELECT t.tableoid,n.nspname as timesheet_group
, t.ts_employeename, t.ts_date
FROM timesheet AS t
INNER JOIN pg_class As p ON t.tableoid = p.oid
INNER JOIN pg_namespace As n ON p.relnamespace = n.oid
WHERE t.ts_date = '2012-01-16' AND t.ts_employeename = 'rrunner';
tableoid | timesheet_group | ts_employeename | ts_date
----------+-----------------+-----------------+------------
2332415 | icecreammakers | rrunner | 2012-01-16
PostgreSQL Q & A
True or False every which way Intermediate
PostgreSQL has aggregate functions called bool_and and bool_or which it's had for as far back as I can remember. What do they do? given rows of premises (things that resolve to booleans), bool_and will return true if all of the premises are true. Similarly bool_or will return true if any of the premises in the set of rows is true. What if however your boolean expressions are not in rows, but instead passed in as a sequence of arbitrary statements of questionable fact. We want a function like bool_or or bool_and that takes an arbitrary number of boolean arguments. Are there functions that fit the bill. Indeed there are, but they don't scream out and say I work with booleans because they fit into a class of function we discussed in The wonders of Any Element and that also happen to be variadic functions. These are none other than greatest and least and they are old timer functions that you can find in most versions of PostgreSQL. We'll demonstrate how to use all 4 with booleans in this article. It must be said that greatest and least are much more useful when applied to other data types like dates and numbers, but we were amused at the parallel with booleans.
Drafting our data
Lets create a table of people and capture their date of birth, eye color, and gender. Then we'll use the various boolean functions to make not so interesting conclusions about these people.
CREATE TABLE people(p_name varchar(50) primary key, dob date, gender char(1), eye_color varchar(20));
INSERT INTO people(p_name,dob,gender,eye_color)
VALUES ('Blue Boy', '1770-10-15','M', 'blue')
, ('Mahatma Gandi', '1869-10-02', 'M', 'brown')
, ('Amelia Earhart', '1897-07-24', 'F', 'blue')
, ('Edwin Land', '1909-05-07', 'M', NULL);
bool_and and bool_or in action
-- do any of our people have blue eyes or over 110 years by gender?
SELECT gender, bool_and(eye_color = 'blue') As all_blue
, bool_or(eye_color = 'blue') As any_blue
, bool_and(age(dob) > '110 years'::interval) As all_over_110
, bool_or(age(dob) > '110 years'::interval) As any_over_110
FROM people
GROUP BY gender;
gender | all_blue | any_blue | all_over_110 | any_over_110
-------+----------+----------+--------------+--------------
F | t | t | t | t
M | f | t | f | t
Positing compound statements with greatest and least
It must be noted that instead of greatest and least, you can use AND / OR. There are pros and cons to each. AND / OR are a bit more verbose but have the benefit of being able to be short-circuited. Sadly greatest/least would we think require all expressions to be resolved and also since it's generic, probably doesn't know that it can stop without evaluating all expressions. If your expressions are simple and not time consuming to process, then the brevity of the statement out-weighs the tediousness of AND/OR.
-- For each answer the question
-- blue, female, and has an a in the name
SELECT p_name
, greatest(eye_color = 'blue', gender = 'F', p_name LIKE '%a%') As any_condition
, least(eye_color = 'blue', gender = 'F', p_name LIKE '%a%') As all_conditions
FROM people
ORDER BY p_name;
p_name | any_condition | all_conditions
----------------+---------------+----------------
Amelia Earhart | t | t
Blue Boy | t | f
Edwin Land | t | f
Mahatma Gandi | t | f
bool_and, bool_or, greatest and least in one breath
One caveat is that bool_and and bool_or similar to other aggregates discard NULLs unless if that is all there is. Similar behavior with greatest and least. This is sometimes desirable and sometimes not.
-- Only caution bool aggs and also least/greatest discard unknowns
-- so if we don't know the eye_color and all known conditions are met
-- , the overall condition is considered met
SELECT eye_color, bool_or(least(eye_color = 'blue', p_name LIKE '%a%')) As any_have_all,
bool_and(greatest(eye_color = 'blue', p_name LIKE '%a%')) AS all_have_any
FROM people
group by eye_color;
eye_color | any_condition | all_conditions
-----------+---------------+----------------
| t | t
blue | t | t
brown | f | t
Basics
PSQL needs a better way of outputting bytea to binary files
Have you ever tried to output a file stored in a bytea column from PostgreSQL using PSQL? It ain't pretty. Andrew Dunstan has a couple of examples of doing this in his article Clever Trick Challenge. This issue has now become very relevant for PostGIS raster use. The reason being is that now that PostGIS in it's 2.0 encarnation can do clipping of rasters, unions of rasters, map algebra, convert geometries to rasters and convert those rasters to various imagery type file formats, people naturally assume it should be trivial to output your new fangled raster query as a jpeg or png etc via, PSQL. Turns out it is not. For those who need to, I've documented an example using one suggestion from Andrew's blog which utilizes the Large object support built into PostgreSQL. It would be nice if this were simpler. I chose this approach because it was the only one that didn't assume a user has Perl installed or is on a Unix system so should work fairly much the same regardless the client OS in use. You can find the example in Outputting Rasters with PSQL. Suggestions on how to improve on this are welcome.
PL Programming
The wonders of Any Element
PostgreSQL has this interesting placeholder called anyelement which it has had for a long time and its complement anyarray. They are used when you want to define a function that can handle many types arguments or can output many types of outputs. They are particularly useful for defining aggregates, which we demonstrated in Who's on First and Who's on Last and several other aggregate articles.
Anyelement / anyarray can be used just as conveniently in other functions. The main gotcha is that when you pass in the first anyelement/anyarray all subsequent anyelement / anyarray must match the same data type as the first anyelement / anyarray.
Anyelement in more than 1 slot
Let us say I had a function that can take in as input any type and return a record with a column that can be any type. A perfect example, I want to create a function that takes 2 elements of the same type, gives me the difference, and returns back the original elements incremented by 1.
CREATE OR REPLACE FUNCTION diff_inc(IN anyelement, IN anyelement
, OUT diff integer, OUT f_val anyelement, OUT l_val anyelement)
RETURNS record
AS
$$
SELECT ($1 - $2)::integer As diff, $1 + 1 As f_val, $2 + 1 As l_val;
$$
language 'sql' IMMUTABLE STRICT;
-- legal --
SELECT (diff_inc('2011-12-31'::date, '2012-01-05'::date)).*;
-- output --
diff | f_val | l_val
-----+------------+------------
-5 | 2012-01-01 | 2012-01-06
-- legal --
SELECT (diff_inc(1, 2)).*;
-- output --
diff | f_val | l_val
------+-------+-------
-1 | 2 | 3
-- not legal --
SELECT (diff_inc('2011-12-31'::date, 5)).*;
-- gives error --
HINT: No function matches the given name and argument types. You might need to add explicit type casts.
ERROR: function diff_inc(date, integer) does not exist
-- legal --
SELECT (diff_inc(2.5, 2.5)).*;
-- gives --
diff | f_val | l_val
------+-------+-------
0 | 3.5 | 3.5
-- not legal --
SELECT (diff_inc(2, 2.5)).*;
-- gives error --
ERROR: function diff_inc(integer, numeric) does not exist
LINE 1: SELECT (diff_inc(2, 2.5)).*;RETURNS TABLE with anyelement
In a prior article we said that RETURNS TABLE and OUT are essentially the same. I was thinking they might behave differently with anyelement. In fact they work the same, so if you prefer the RETURNS TABLE syntax instead of using OUT params, you can define the above function like:
CREATE OR REPLACE FUNCTION diff_inc2(IN anyelement, IN anyelement)
RETURNS TABLE(diff integer, f_val anyelement, l_val anyelement)
AS
$$
SELECT ($1 - $2)::integer As diff, $1 + 1 As f_val, $2 + 1 As l_val;
$$
language 'sql' IMMUTABLE STRICT;
Application Development
Rendering PostGIS Raster graphics with LibreOffice Base Reports Intermediate
I was excited to learn from Pasha Golub's blog LibreOffice Base 3.5 now comes packaged with native PostgreSQL driver so no separate configuration is required. The connection string syntax follows the old SBC native driver of prior OpenOffice versions we itemized in Using OpenOffice Base with PostgeSQL.
What I really wanted to do with it is experiment with its graphical rendering capabilities. As discussed in PSQL needs a better way of outputting bytea one of the frequently asked questions on the PostGIS list by folks using the new not yet officially released (alpha5 recently released) functionality in PostGIS 2.0 is how to render rasters with common variety tools. I suspected Base was a capable option, but had never tested it to confirm. Since I was installing new LibreOffice 3.5, I thought this might be a good test of its metal.
Connecting to a PostgreSQL database
As said the native PostgreSQL driver in 3.5 just uses the SDBC syntax, so I was able to connect to my database by typing this in for the Database URL:
host=localhost port=5440 dbname=postgis20_samplerIf you want to not be prompted for username and password, for newer odb, seems you have to include in the connection string like so.
host=localhost port=5440 dbname=postgis20_sampler user=postgres password=whatever
My port is pretty non-standard since I've got like 20 different versions of PostgreSQL installed on my local pc for development. Your port would most likely be 5432.
Using Ad-Hoc queries that return images in Base
What I really wanted to do was render a randomly complex query that returns images like this one.
SELECT foo.id, ST_AsPNG(
ST_AsRaster(
CASE WHEN id = 1 THEN
ST_Buffer(
ST_MakeLine(
ST_Translate(
ST_Transform(foo.geom,26986),x*random()*500,y*random()*500)
)
,2)
ELSE
ST_ConcaveHull(
ST_MakeLine(
ST_Translate(
ST_Transform(foo.geom,26986),x*random()*500,y*random()*500)
),0.90)
END
, 200,200,ARRAY['8BUI', '8BUI', '8BUI'], ARRAY[100*foo.id,154,118], ARRAY[0,0,0])
) As png_img
FROM (VALUES (1, ST_GeomFromText('POINT(-71.124 42.2395)',4326) )
, (2, ST_GeomFromText('POINT(-71.555 42.4325)',4326) )
) AS foo(id, geom)
CROSS JOIN generate_series(1,10) As x
CROSS JOIN generate_series(1,20) As y
GROUP BY foo.id;
So steps:
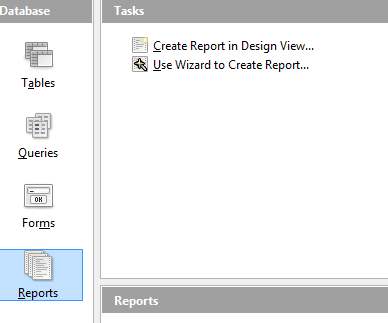
- Select Reports and in Task choose Create Report in Design View as shown in:
- Pick SQL Command from Data Content tab. If you don't see Data content tab, make sure to click the grey
area right below the Page footer in the design view
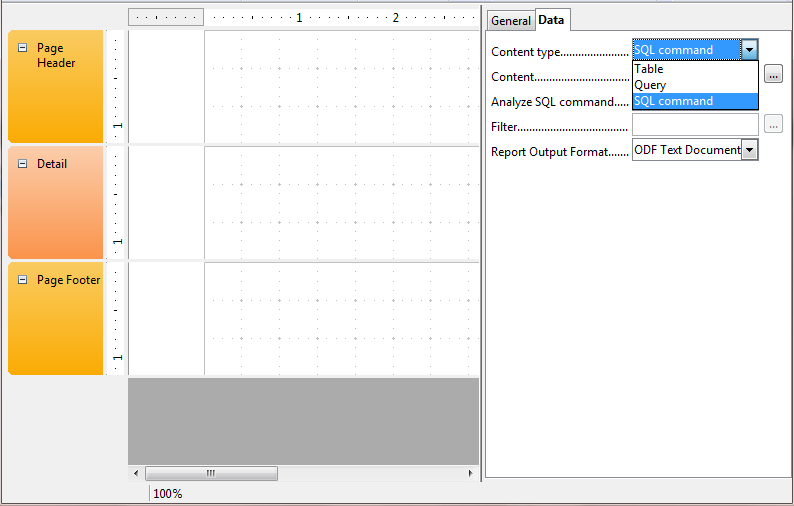
- Next click the ... next to the Content, which will pop open a designer with tables to pick etc, close the table dialog.
Real database programmers don't like being constrained by query designers and want to write real SQL
, so go to the view menu and Switch Design View off as shown here
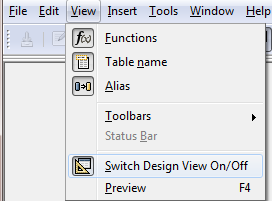 . If you are not
a real database programmer, just humor me and pretend you are.
. If you are not
a real database programmer, just humor me and pretend you are. - Cut and paste your finely crafted SQL masterpiece into the blank window
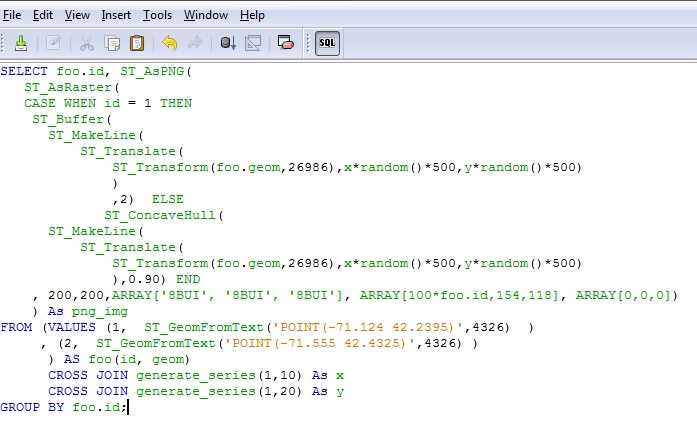
- UPDATE: In LibreOffice 4.0 they introduced an SQL Parser which prevents you from writing some advanced queries such as ones involving CTEs. This particular query is one that confounds the parser and it marks as invalid.Turn off the parser by File->Edit->Run SQL command directly
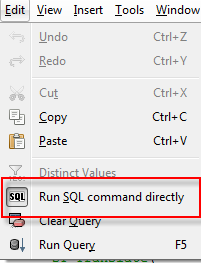
- click the run as SQL command directly SQL icon
 and then the
and then the  green save icon.
green save icon. - If your SQL is valid, you should see a list of columns from your query like this:
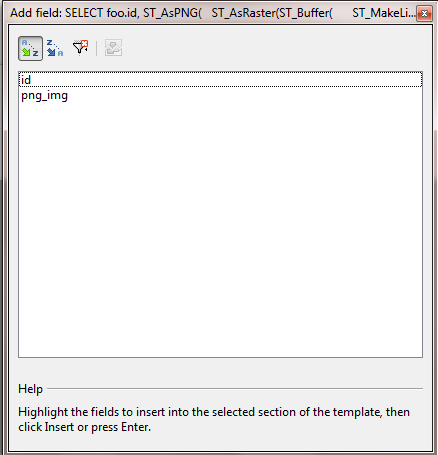
- Drag the fields on the design screen and fuss with them. After fussing, I got a design view like
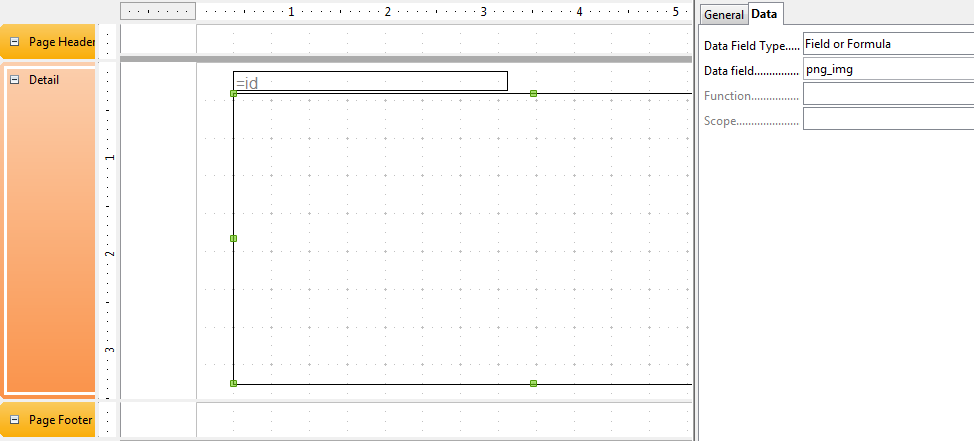
- Click the
 which produced an output
which produced an output
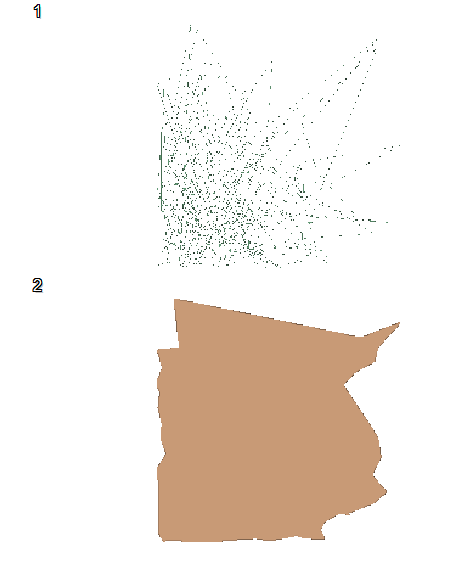 that can also be output as pdf or html page.
that can also be output as pdf or html page.
It's not my best work, but proves the point that yes you can write arbitrarily complex SQL even involving queries that output images and have LibreOffice base render them.