Table Of Contents
Dennis Ritchie - Inventor of C: In Memorium
Many PostGIS FOSS4G 2011 videos have landed
PostgreSQL Array: The ANY and Contains trick Intermediate
Sweat the small stuff, it really matters
Lessons learned Packaging PostGIS Extensions: Part 2 Advanced
From the Editors
Improving speed of GIST indexes in PostgreSQL 9.2 Intermediate
This is about improvements to GIST indexes that I hope to see in PostgreSQL 9.2. One is a patch for possible inclusion in PostgreSQL 9.2 called SP-GiST, Space-Partitioned GiST created by Teodor Sigaev and Oleg Bartunov whose basic technique is described in SP-GiST: An Extensible Database Index for Supporting Space Partitioning Trees. For those who don't know Teodor and Oleg, they are the great fellows that brought us many other GiST and GIN goodnesses that many specialty PostgreSQL extensions enjoy -- e.g. PostGIS, trigrams, ltree, pgsphere, hstore, full-text search to name a few.
Another is a recent one just committed by Alexander Korotkov which I just recently found out about on New node splitting algorithm for GIST and admit I don't know enough about to judge. I have to admit to being very clueless when it comes to the innards of index implementations so don't ask me any technical details. It's one of those short-comings among the trillion others I have that I have learned to accept will probably never change.
What the SP-GIST patch will provide in terms of performance and speed was outlined in PGCon 2011: SP-GiST - a new indexing infrastructure for PostgreSQL Space-Partitioning trees in PostgreSQL.
What it provides specifically for PostGIS is summarized in Paul's call for action noted below. As a passionate user of PostGIS ,ltree, tsearch, and hstore, I'm pretty excited about these patches and other GIST and general index enhancements and there potential use in GIST dependent extensions. I'm hoping to see these spring to life in PostgreSQL 9.2 and think it will help to further push the envelope of where PostgreSQL can go as a defacto platform for cutting-edge technology and scientific research. I think one of PostgreSQL's greatest strength is its extensible index API.
Paul's PostGIS newsgroup note about seeking funding for faster GIST indexes , work done so far on SP-GIST and call for further action is rebroadcast in it's entirety here.
Thanks to the sponsorship of Michigan Technological University, we now have 50% of the work complete. There is a working patch at the commitfest https://commitfest.postgresql.org/action/patch_view?id=631 which provides quad-tree and kd-tree indexes. However, there is a problem: unless the patch is reviewed and goes through more QA/QC, it'll never get into PostgreSQL proper. In case you think I am kidding: we had a patch for KNN searching ready for the 9.0 release, but it wasn't reviewed in time, so we had to wait all the way through the 9.1 cycle to get it. I am looking for sponsors in the $5K to $10K range to complete this work. If you use PostgreSQL in your business, this is a chance to add a basic capability that may help you in all kinds of ways you don't expect. We're talking about faster geospatial indexes here, but this facility will also radically speed any partitioned space. (For example, the suffix-tree, which can search through URLs incredibly fast. Another example, you can use a suffix tree to very efficiently index geohash strings. Interesting.) If you think there's a possibility, please contact me and I will send you a prospectus you can take to your manager. Let's make this happen folks! Paul
On Fri, May 27, 2011 at 10:45 AM, Paul Ramsey wrote: > One of the eye-opening talks of PgCon last week was the presentation > from Oleg Bartunov and Teodor Sigaev on their work on spatial > partitioning indexes in PostgreSQL. Oleg and Teodor are the > maintainers of the GiST framework we use for our r-tree, and are > proposing a new framework to allow quad-tree and kd-tree > implementations in PostgreSQL. > > http://www.pgcon.org/2011/schedule/events/309.en.html > > The upshot is, this new approach is as much as 6-times faster than the > r-tree (at least for points). If you're interested in seeing PostGIS > indexes get vastly faster, consider funding this project. Get in touch > with me directly for details. > > http://blog.opengeo.org/2011/05/27/pgcon-notes-3/ > > P. >
From the Editors
Dennis Ritchie - Inventor of C: In Memorium
It is with sadness that I learned of the passing of Dennis Ritchie - inventor of C and who made much of Unix, other operating systems, and many software (including Postgres) possible. More details at Remembering Dennis Ritchie: Software Pioneer and Dennis Ritchie, in Memoriam.
Dennis Ritchie co-authored the book, The C Programming Language, a classic, which many of my peers grew up with. It was one of the textbooks at MIT for Civil Engineering 1.00 when we were attending when the course was essentially an introduction to programming with C.
The harsh irony is that when Steve Jobs passed away I was probably the only one around me who felt no remorse and hoped the curve fanaticism Jobs fueled would die with him. When Dennis Ritchie passed away I was probably one of the few around me who knew who he was and appreciated the great contributions he made to the computer industry.
From the Editors
Many PostGIS FOSS4G 2011 videos have landed
FOSS 4G 2011 Videos. My resident PostGIS developer strk says he can't see them because blip.tv is using some sort of proprietary video swf format. I can't really tell what he is talking about. Does anyone know if fosslic videos are available in other formats like ogg or a Gnash swf viewer compatible format?
We mentioned in prior article Our FOSS4G 2011 the new Stuff and provided the slides in that article. Now we have the video to go with it.
Here is a partial list of PostGIS videos:- Paul's standard State of PostGIS He ran out of time so our's is more like a continuation.
- PostGIS 2.0 the new Stuff (our presentation)
- PostGIS Raster 2.0 - store, manipulate and analyze raster Pierre Racine
What's new and upcoming in PostgreSQL
FOSS4G 2011 PostGIS the new stuf
We attended FOSS4G this year in Denver, Colorado. Friday was a PostGIS bonanza with 5 PostGIS talks back to back including ours. The crowd was huge. All the PostGIS talks as I recall were so packed that there were not enough seats to accommodate everyone. A more comprehensive detail of the events is described on OpenGeo FOSS4G Day #5
We admit to overstuffing our slides with SQL and ran short on time at the end. Leo complained and vowed to do a better job next time. We really weren't expecting such a large crowd. Admittedly I'm all for the after conference experience which is much longer than the conference which is why I tend to make slides that are very dense. WARNING: The following slides feature SQL doing unconventional things suitable only for mature audiences. Viewer discretion is adviced.. You can check out our slides here PostGIS 2.0 the new stuff.
CREATE EXTENSIONs
We've started work on CREATE EXTENSIONS and have it functional which you can see shown in the pgAdmin snapshots in the slides and the pictures below.
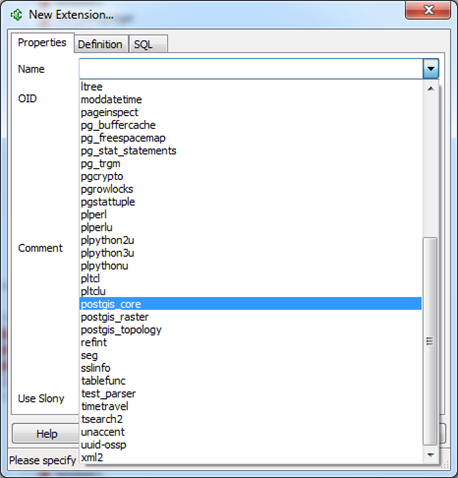
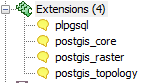 ;
;
In the PostGIS code sprint we attended on Saturday, one of the decisions was to combine what we call core with postgis_raster and make raster compilation not optional. To make this easier, we will be simplifying some of the requirements for compilation of raster like working on making raster2pgsql a regular binary not dependant of Python and also just making the python check a warning. The only python dependency we have in raster is the loader.
There are some other kinks that need to be worked out in the extensions mostly to do with uninstall, install from unpackaged, upgrading, move to different schema. There are some errors we are getting which may be issues with the extension model or the way we are executing it. More on that later.
KNN GIST
Lots of people have been asking about this. It is not currently available in trunk, but Paul has funding to make it happen so its planned for PostGIS 2.0 release.
When will PostGIS 2.0 be released
Much later than I would like. We decided to have our code freeze November 30th, first beta December 1st and final release probably early February. I think we had a lot of scope creep, mostly becasue we had no well-defined scope to speak of. I don't think that was a bad thing though. It was more fun to see the features unfold than to have them granularly defined on the outset.
What's new and upcoming in PostgreSQL
KNN Gist for PostGIS in Place
Lots of people have been asking the never ending question of when PostGIS is going to get on the band wagon and support KNN GIST like other GIST based types trigrams, full text search etc. Well it's happened in PostGIS 2.0 and now committed. More of the gory details at Indexed Nearest Neighbour Search in PostGIS. In short this will make point / point distance searches and rankings way way faster and help also with other distance searches by providing approximations to start with.
We are still preparing the PostgreSQL 9.1 2.0 32-bit windows builds that will have this functionality and should have that ready in the next day or so.
To summarize what you can expect. We spent a lot of time discussing and were torn between a box distance operator <#> and a centroid box distance operator <->, so we ended up having both. The reason being is that for some kinds of geometries e.g. streets that aren't diagonal a box distance operator seems to be a much better approximation of distance than a centroid box distance operator. For points of course the two concepts are the same and not an approximation so point / point distance you'd be better off using the new KNN sorting than ST_Distance + ST_DWithin as we have suggested in past. I'll be doing some benchmarks in the coming weeks comparing the old way and speed differences you can expect and perhaps throwing together box and centroid cocktails that combine the two weapons into thought provoking WTFs (or as Dave Fetter would say "That's very Rube Goldberg of you").
I suspect I'll probably be sticking with <#> because I like the symbol better and I was one of the ones fighting for it :).
PostgreSQL Q & A
Bulk Revoke of Permissions for Specific Group/User role Intermediate
UPDATE Turns out there is a simpler way of getting rid of roles that have explicit permissions to objects as Tom Lane pointed out in the comments.
DROP OWNED BY some_role;Will drop the permissions to objects a user has rights to even if they don't own the objects. Of course this needs to be applied with caution since it will drop tables
and other things you don't want necessarily dropped. So it is best to first run a:
REASSIGN OWNED BY some_role TO new_role;
And then run the DROP OWNED BY.
The REASSIGN OWNED BY which is what we did originally is not sufficient since it doesn't drop the permissions or reassign
them as we assumed it would. This is noted in the docs.
And then you will be allowed to
DROP ROLE some_role
One of the things that is still tricky in PostgreSQL is permission management. Even though 9.0 brought us default privileges and the like, these permissions aren't retroactive so still a pain to deal with if you already have objects defined in your database.
One of the annoyances we come across with is deleting roles. Lets say you have a role and it has explicit permissions to an object. PostgreSQL won't allow you to delete this role if it owns objects or has explicit permissions to objects. In order to delete it seems you have to go in and clear out all those permissions. To help with that -- we wrote a quickie script that will generate a script to revoke all permissions on objects for a specific role. It looks like this:
WITH r AS (SELECT 'role_to_revoke'::text As param_role_name)
SELECT DISTINCT 'REVOKE ALL ON TABLE ' || table_schema || '.' || table_name || ' FROM ' || r.param_role_name || ';' As sql
FROM information_schema.table_privileges CROSS JOIN r
WHERE grantee ~* r.param_role_name
UNION ALL
SELECT DISTINCT 'REVOKE ALL ON FUNCTION ' || routine_schema || '.' || routine_name || '('
|| pg_get_function_identity_arguments(
(regexp_matches(specific_name, E'.*\_([0-9]+)'))[1]::oid) || ') FROM ' || r.param_role_name || ';' As sql
FROM information_schema.routine_privileges CROSS JOIN r
WHERE grantee ~* r.param_role_name
UNION ALL
SELECT 'REVOKE ALL ON SEQUENCE ' || sequence_schema || '.' || sequence_name || ' FROM ' || r.param_role_name || ';' As sql
FROM information_schema.sequences CROSS JOIN r ;
Our script if we run by replacing 'role_to_revoke' with 'public' will look something like this:
--- output -- REVOKE ALL ON TABLE pg_catalog.pg_tables FROM public; : : REVOKE ALL ON FUNCTION public.st_crosses(geometry, geometry) FROM public; : REVOKE ALL ON FUNCTION public.st_addband(torast raster, fromrast raster, fromband integer) FROM public; : REVOKE ALL ON SEQUENCE topology.topology_id_seq FROM public;
Some items in this script probably look cryptic to the untrained or unknowing eye:
-
information_schema goodness. As we've mentioned before the information_schema is a more or less ANSI standard schema you will find on other relational databases that stores all sorts of meta-data such as the names of tables, views, functions and in addition the priviledges for each. It unforntatunely is not complete but we use it wherever we can just because it works on multiple databases we work with so limits the number of things we need to remember.
-
routine information_schema views. Tables with routine in the name provide information about functions and stored procedures. The routine_privileges view lists all the permissions for each stored procedure/function. The grantee being the role who has the permission and grantor the role that granted the permission. Sadly this talbe does not exist in all databases supporting information_schema. MySQL has it for example, but SQL Server in any version I can think of does not have it though it does have a routines view.
-
What the hell is this: pg_get_function_identity_arguments( (regexp_matches(specific_name, E'.*\_([0-9]+)'))[1]::oid). Okay this is us cheating a bit. In the routine_privileges view, there is a column called specific_name which is a unique across the database name of a function. So this means that overloaded functions will all have the same routine_name but different specific_name. PostgreSQL formulates the specific_name by appending _ followed by the procedure object identifier (oid) of the function. The PostgreSQL function pg_get_function_identity_arguments given the object identifier (oid) of a procedure, will return a comma separated list of the argument types that are inputs to the function. Our regular expression pulls this function oid out and casts it back to an oid so it can be used by this function.
-
WITH -- this script only works in 8.4 and above since it uses Common Table Expressions (CTE). One of my favorite uses for CTE is for storing variables to be used in later queries. It's an SQL idiom we use often to emulate procedural variable declaration. So in this the r CTE is used in the output statement to filter the records.
PostgreSQL Q & A
PostgreSQL Array: The ANY and Contains trick Intermediate
One of the main features I love about PostgreSQL is its array support. This is a feature you won't find in most relational databases, and even databases that support some variant of it, don't allow you to use it as easily. It is one of the features that makes building aggregate functions wicked easy in PostgreSQL with no messy compiling required. Aside from building aggregate functions, it has some other common day uses. In this article, I'll cover two common ways we use them which I will refer to as the ANY and Contains tricks.
I like to think of this approach as YeSQL programming style: how SQL can be augmented by more complex data types and index retrieval mechanisms. Arrays and many other data types (spatial types, keyvalue (hstore), ltree etc) are far from relational structures, yet we can query them easily with SQL and can even relate them.
Using comma separated items in an SQL ANY clause
Ever have a piece of text like this: apple,cherry apple,avocado
or a set of integer ids like this 1,5,6
which perhaps you got from a checkbox picklist? You need to find out the details of the
chosen products.
Well the first steps is to convert your string to an array like so:
SELECT '{apple,cherry apple, avocado}'::text[];
If it's a set of integers you would do.
SELECT '{1,4,5}'::int[];
Which converts your list to an array of: apple,"cherry apple",avocado
or 1,4,5
Now you combine it with your detail query
Let's say your data looked something like this:
CREATE TABLE products(
product_id serial PRIMARY KEY
,product_name varchar(150)
,price numeric(10,2) ) ;
INSERT INTO products(product_name, price)
VALUES
('apple', 0.5)
,('cherry apple', 1.25)
,('avocado', 1.5),('octopus',20.50)
,('watermelon',2.00);
Now to get the details about the products the user selected
SELECT product_name, price
FROM products
WHERE
product_name = ANY('{apple,cherry apple,avocado}'::text[]);
SELECT product_name,price
FROM products
WHERE
product_id = ANY('{1,4,5}'::int[]);
Let us say we needed to convert the id array back to a comma delimeted list. This will work in pretty much any version of PostgreSQL
SELECT array_to_string(ARRAY(SELECT product_name
FROM products
WHERE
product_id = ANY('{1,4,5}'::int[]) ), ',') As prod_list;
Which will give you an output: apple,octopus,watermelon
Now if you are using PostgreSQL 9.0 or higher. You can take advantage of the very cool string_agg function and combine that with the even cooler ORDER BY of aggregate functions if you want your list alphabetized. The string_agg approach comes in particularly handy if you are dealing with not one user request but a whole table of user requests. The string_agg equivalent looks like below --NOTE: it's not much shorter, but is if you are dealing with sets and can employ the GROUP BY person_id or some such clause. It will also be faster in many cases since it can scan the data in one step instead of relying on sub queries:
SELECT string_agg(product_name, ',' ORDER BY product_name) As prod_list
FROM products
WHERE product_id = ANY('{1,4,5}'::int[]) ;
Using arrays in column definitions and Contains @> operator
Of course for casual lists, arrays are great for data storage as well. We use them with caution when portability to other databases is a concern or referential integrity is a concern. Still they have their place.
Let's say we have a restaurant matching system where the user selects from a menu of foods they'd like to eat and we try to find a restaurant that has all those foods. Our very casual database system looks like this. Our objective is to write the shortest application code we can get away with that is still fairly efficient. The foods table would be used just as a lookup for our pick list:
CREATE TABLE food(food_name varchar(150) PRIMARY KEY);
INSERT INTO food (food_name)
VALUES ('beef burger'),
('veggie burger'), ('french fries'),
('steak'), ('pizza');
CREATE TABLE restaurants(id serial PRIMARY KEY,
restaurant varchar(100), foods varchar(150)[]);
--yes you can index arrays
CREATE INDEX idx_restaurants_foods_gin
ON restaurants USING gin (foods);
INSERT INTO restaurants(restaurant, foods)
VALUES
('Charlie''s', '{beef burger,french fries,pizza}'::varchar[]),
('Rinky Rink', '{beef burger,veggie burger}'::varchar[]),
('International', '{beef burger,spring rolls,egg rolls,pizza}'::varchar[]);
Our application allows users to pick foods they want for a meal and matches them up with all restaurants that have those items. For this trick we use the array contains operator to return all restaurants that contain in their food list all the foods the user wants to partake of in this meal. Our resulting query would look something like:
SELECT restaurant
FROM restaurants
WHERE foods @> '{beef burger, pizza}'::varchar[];
Which outputs the below. Our dataset is so small that the index doesn't kick in, but if we have a 10000 or more restaurants we'd see the GIN index doing its magic.
restaurant --------------- Charlie's International
As a final food for thought, PostgreSQL supports multi-dimensional arrays as well which has some interesting uses as well. Perhaps we'll delve into some examples of multi-dimensional arrays in another article.
Basics
SQL Server to PostgreSQL: Converting table structure Beginner
We've been working on converting some of our SQL Server apps to PostgreSQL. In this article we'll describe some things to watch out for and provide a function we wrote to automate some of the conversion.
Although both databases are fairly ANSI-SQL compliant, there are still differences with their CREATE TABLE statements, data types, and how they handle other things that makes porting applications not so trivial.
SQL Server and PostgreSQL data type differences and equivalents
Here are a couple of key differences and similarities in data types between the two. Some are easy to resolve and others are not.
- SQL Server bit vs. PostgreSQL boolean:
SQL Server, similar to most other relational databases I can think of doesn't really have a true boolean type even in SQL Server 2008 and upcoming version. Leo really loves the PostgreSQL boolean type so much so that he's willing to trade portability for having a real true/false data type. PostgreSQL also has a bit which can be more than 1 in length, but it doesn't cast naturally to a boolean type in applications like SQL Server's bit or PostgreSQL boolean so we suggest you stay away from it for boolean use. Most tools .NET etc. we work with cast both SQL Server bit and PostgreSQL boolean to the boolean type of the application language. When writing raw SQL, however, they are different beasts.
In SQL Server you would use a bit in SQL as if it were an integer - sorta. There are nuisances, such as you can't add bits unless you cast them to integers etc. but for sake of argument we can wave our hands and call it a small integer that would be expressed LIKE:
WHERE is_active = 1
WHERE is_active = 0In PostgreSQL, you would use a boolean as if it were a boolean and treating it like a 0 / 1 number is not allowed unless you define type casts for such behavior. So the way you would use PostgreSQL boolean in a where would take form:
WHERE is_active = true
WHERE is_active
WHERE is_active = false
WHERE NOT is_active
PostgreSQL does have auto casts for boolean to text which allows you to write Oracle compatible syntax- any of these will cast ('TRUE','FALSE','true','t','f', 'false')
WHERE is_active = 'FALSE'
WHERE is_active = 'TRUE'
are all valid constructs in PostgreSQL but invalid in SQL Server and you could use 0 and 1 too if you install some autocasts in your database as we described in Using MS Access with PostgreSQL which while designed for MS Access work equally well when writing raw SQL.
- SQL Server 2005/2000 datetime vs. PostgreSQL timestamp with time zone, timestamp without time zone, date, time .
This small little annoyance is a less of a concern in SQL Server 2008+ since 2008 introduced (DATE, TIME, DATETIMEOFFSET) which are equivalent to PostgreSQL types so mapping is much cleaner for 2008.
If you are converting from SQL Server 2005/2000 you have to consciously think about whether the columns you had the old way should really be timestamps or dates or even times and if you really want the time zone following your data around.
For most of the apps we are porting, we don't ever intend to go back nor have it work with anything but PostgreSQL, so we've been taking liberties using syntax that will probably not be portable such as using PostgreSQL array support, complex type, and built-in regular expression support shamelessly just because it makes so many tasks so much succinct and faster.
It's a hard decision to make consciously because of the WHAT IFS (not just about betting on success of PostgreSQL, but the fact that you can't market your work to people who need it to work for a different database platform or even a lower version of a database platform). Product lock-in is a reality even when you have no vendors and when you are using open source. Standards are there to minimize product/vendor lock-in, but they often fall short of covering your needs. Product-lockin is a step that should not be taken lightly and should be considered on an application by application basis. It is best to make the decision consciously and play out the pros / cons of what you are gaining and losing. Most of our apps involve lots of stats, complex analytics of which we've decided it's much more efficient to make the database the engine to perform that than to try to write application code so that it works across multiple database platforms. Database lock-in is the lesser of other evils.
The big PITA: Column Casing
In SQL Server the standard for casing is Pascal case / camel case as described in our article Of Camels and People: Converting back and forth from Camel Case, Pascal Case to underscore lower case and in PostgreSQL people usually prefer underscores and lower case because upper or mixed case would need constant ugly quoting of columns. SQL Server can get away with this without enduring penalty because while it respects the casing of the columns in design, it is case insensitive when it is used in an SQL statement.
So for example if you had a table structure in SQL Server with columns named:
PersonID, FirstName, LastName
you can reference them as personid, firstname, FIRSTNAME etc..
If you want to keep your code more or less working without changing anything, you are best off just getting rid of the casing of SQL Server columns so you don't need to quote them in PostgreSQL. Same issue holds for Oracle that it is sensitive to casing of tables, except in Oracle case columns need to be uppercase to not require quoting and in PostgreSQL, columns need to be lower case to not require quoting.
However if you get really hot an bothered about not having word like breakages in your column names that casing or underscores provide, the thought of always having to quote columns sounds like hell, and this is an application you expect to live with for a while, you may just want to bite the bullet as we often do and change the casing when you migrate. YES, this means you probably have to rewrite a good chunk of your code. We like to think of it as providing an opportunity to refactor our code. I LOVE refactoring.
The Quick and Dirty PostgreSQL function to convert SQL Server create table structure
To automate some of the process of converting our table structures from SQL Server to PostgreSQL we opted to write a PostgreSQL function to do it so that we could completely control how it is done.
One of the reasons we are porting some of apps is that PostgreSQL string manipulation functions and array support makes so many things easier. One of those things is this. SQL Server by comparison has pretty pathetic built-in string manipulation features.
CREATE OR REPLACE FUNCTION convert_mssqlddl2pgsql(sql text,
change_camel_under boolean, default_not_nulls boolean DEFAULT true,
replace_dbo_with_schema text DEFAULT NULL)
RETURNS text AS
$$
DECLARE
var_sql text := sql;
r record;
BEGIN
IF change_camel_under THEN
-- only match captilas [A-Z] that are preceded and followed by lower case [a-z]
-- replace the whole match with preceding lowercase _uppercase following lowercase
var_sql := regexp_replace(var_sql, E'([a-z])([A-Z])([a-z]?)', E'\\1\_\\2\\3','g');
END IF;
var_sql := lower(var_sql);
var_sql := replace(var_sql,'[dbo].', COALESCE('[' || replace_dbo_with_schema || '].',''));
var_sql := replace(var_sql,'on [primary]', '');
FOR r IN (SELECT * FROM ( VALUES ('datetime', 'timestamp with time zone', 'CURRENT_TIMESTAMP'),
('bit', 'boolean', 'true'),
('varchar(max)', 'text', ''),
('nvarchar', 'varchar', ''),
('tinyint','smallint', '0') ,
('[int] identity(1,1)', 'serial', NULL)
) As f(ms,pg, def)) LOOP
IF default_not_nulls AND r.def IS NOT NULL THEN
var_sql := replace(var_sql, '[' || r.ms || '] not null', '[' || r.ms || '] not null DEFAULT ' || r.def);
END IF;
var_sql := replace(var_sql, '[' || r.ms || ']',r.pg) ;
var_sql := replace(var_sql, r.ms ,r.pg) ;
END LOOP;
var_sql := regexp_replace(var_sql, '[\[\]]','','g');
var_sql := regexp_replace(var_sql,'(primary key|unique) (clustered|nonclustered)', E'\\1', 'g');
--get rid of all that WITH (PAD_INDEX ...) that sql server generates for tables
-- so basically match any phrase WITH ("everything not containing )" )
var_sql := regexp_replace(var_sql, 'with \([^\)]+\)', '','g');
-- get rid of asc in column constraints
var_sql := regexp_replace(var_sql, '([a-z]+) asc', E'\\1','g');
-- get rid of collation
-- for PostgreSQL 9.1 might want
-- to just change it to 9.1 syntax
var_sql := regexp_replace(var_sql, 'collate [a-z0-9\_]+', '','g');
RETURN var_sql;
END;
$$
LANGUAGE plpgsql IMMUTABLE;
-- EXAMPLE USAGE - convert camel to under score, dbo to public, not null to default defined constants
SELECT convert_mssqlddl2pgsql('
CREATE TABLE [dbo].[Contacts](
[ContactID] [int] IDENTITY(1,1) NOT NULL,
[FirstName] [varchar](50) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[LastName] [varchar](50) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[CompanyID] [varchar](50) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[AddDate] [datetime] NOT NULL,
CONSTRAINT [PK_Contacts] PRIMARY KEY CLUSTERED
(
[ContactID] ASC
)WITH (IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
', true, true, 'public');
-- output --
create table public.contacts(
contact_id serial not null,
first_name varchar(50) null,
last_name varchar(50) null,
company_id varchar(50) null,
add_date timestamp with time zone not null DEFAULT CURRENT_TIMESTAMP,
constraint pk_contacts primary key
(
contact_id
)
)
-- EXAMPLE USAGE - Don't convert to under score
SELECT convert_mssqlddl2pgsql('
CREATE TABLE [dbo].[Contacts](
[ContactID] [int] IDENTITY(1,1) NOT NULL,
[FirstName] [varchar](50) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[LastName] [varchar](50) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[CompanyID] [varchar](50) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[AddDate] [datetime] NOT NULL,
CONSTRAINT [PK_Contacts] PRIMARY KEY CLUSTERED
(
[ContactID] ASC
)WITH (IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
', false, true, 'public');
-- output --
create table public.contacts(
contactid serial not null,
firstname varchar(50) null,
lastname varchar(50) null,
companyid varchar(50) null,
adddate timestamp with time zone not null DEFAULT CURRENT_TIMESTAMP,
constraint pk_contacts primary key
(
contactid
)
) Basics
Sweat the small stuff, it really matters
In most release notices, it's the big shiny sexy features that get all the glamor, but in reality on day to day use
it's the small usability enhancements that make the most difference. I'm reminded about this now that I'm working
on upgrade scripts and extensions for PostGIS. There are a couple of new features that make application upgrades easier that I
regret not having in older versions of PostgreSQL we support and additional ones I had in other databases that I find lacking in PostgreSQL. PostgreSQL 8.2 for example brought us DROP IF EXISTS ...
and all I can say is thank goodness we dropped support of prior versions of PostgreSQL in PostGIS 1.4 otherwise developing upgrade scripts would have been more of a nightmare.
PostgreSQL 8.4 introduced the ability to add additional columns to a view using CREATE OR REPLACE VIEW as
long as those columns were at the end of the view which Gabrielle Roth demonstrates an example of in This week’s find: CREATE OR REPLACE VIEW
If you were a MySQL user or application developer not having such features would be one reason to frown on PostgreSQL
and MySQL users and other database converts still have reasons to frown for lack of usability features they had
in their other database that they feel naked without in PostgreSQL.
In 9.1 we got two new DDL commands not much talked about that I am very excited about.
CREATE TABLE .. IF NOT EXISTS. I can't tell you how many times I've heard MySQL users whine about the lack of this in PostgreSQL and I felt their pain. It would be really nice to have this feature for other things such as TYPES or even possibly a CREATE OR REPLACE TYPE which would allow some alteration of types like adding attributes at the end.- ALTER TYPE ..[ADD ATTRIBUTE] [RENAME ATTRIBUTE] [ADD VALUE]. The [ADD VALUE] is a clause specific to ENUM types which allows you to add new enum values before or after an existing. The lack of that feature in prior versions was the major reason I stayed away from enums.
- And of cause my favorite CREATE EXTENSTION ALTER EXTENSION family which admittedly do get talked about a lot more often and which I'll discuss more in a later article.
I know it sounds like I'm complaining. That's because I am. Honestly though, I think the first step to caring about something is really taking notice of its flaws and wanting to change them. The strength of an open source project is the ease with which it allows its developers and users to have a great impact on its direction. This is something I do think PostgreSQL excels much much better than most open source projects. I find a ton of flaws in PostGIS I'd like to change and have and I am greatful that PostGIS, like PostgreSQL is not resistant to change if the community wants it. If you are going to take notice of flaws in other products without admitting to your own or admitting that some things are easier in other products and learning from them, then you are a hypocrite or living in a closet. Now getting back to my complaining. Things I miss in PostgreSQL that I had in others which I'm sure I'm not alone.
- Being able to change a table column type of a table column that is used in a VIEW and have PostgreSQL just correct the type in the view or allow me the option to change it later. This is something we had in SQL Server which Leo whines about often. Actually Leo's whining is more annoying than the actual problem itself. The notice is at least very descriptive which is more than I can say for other databases.
- Being able to reorder columns in a table. Again something fairly trivial to do in SQL Server and MySQL but not possible in PostgreSQL.
Using PostgreSQL Extensions
Lessons learned Packaging PostGIS Extensions: Part 1 Intermediate
In prior articles we talked about the new PostgreSQL 9.1 extension model and upcoming PostGIS 2.0 extensions which we have experimental builds of so far. In this article and other's to follow, we shall provide a documentary of our venture into this new extensions world. We'll discuss some of the obstacles we had with building extensions, lessons learned, and foolishness exposed, with the hope that others can learn from our experience.
First off, the upcoming PostGIS 2.0 extensions will be packaged as at least two extensions -- postgis which will contain both PostGIS geometry/geography types, functions, meta views and tables as well as raster type and associated functions and tables. Topology support, while a part of upcoming PostGIS 2.0, will be packaged as a separate extension called postgis_topology. The main reason for breaking topology out as a separate extension is that it is always stored in a schema called topology and is not relocatable to another schema. The way the current extension model works, all the parts of your extension should live in the same schema. Later we plan to package tiger geocoder as an extension, but this one probably makes more sense to live on http://pgxn.org/ since it is only of interest to United States users, , is purely plpgsql with dependency on PostGIS, and we had beefed it up as part of a consulting contract for a company running PostGIS 1.5. It's the only piece documented in PostGIS 2.0 that works on 1.5 as well (aside from the tiger toplogy loader which has dependency on toplogy), although it has always lived as an extra in the PostGIS code base.
We'll probably package postgis_legacy_functions as an extension too for those people who badly need those 500 alias functions I chucked.
We mentioned in our prior article that we ran into some issues with how our extension worked -- e.g. topology referencing the postgis extension. Most of these turned out just to be ignorance on my part as to how the different pieces fit together and I'll elaborate on these.
Much of what will be described here is also documented in Packaging Related Objects into an Extension.
In the future I'm hoping we'll also see plr and pgrouting packaged as extensions which are common favorites of PostGIS users.
What is an extension good for?
First off, why do you even want to use the extension model?
One line statement to install a set of functions in a database that are aware of the fact that they exist as a unit.
CREATE EXTENSION postgis_topology;One line statement to bundle loose functions as a contiguous unit.
CREATE EXTENSION postgis_topology FROM unpackaged;- Ability to upgrade to micro or minor versions of a set of functions again with a one liner that looks like this:
ALTER EXTENSION postgis_topology UPDATE TO '2.0.0a1'; - Ability to drop a package of functions, tables, types etc. with a single statement
DROP EXTENSION postgis_topology;Or if you really really want to drop everything dependent on an extension, including YOUR DATA
DROP EXTENSION postgis_topology CASCADE; - A declarative way of stating that a set of functions has a dependency with another extension and alerting the user to that during installation.
For example -- this is the message I would get if I tried to run:
CREATE EXTENSION postgis_topology;
without postgis extension first being installedERROR: required extension "postgis" is not installed
- A quick way for user's to know what the hell your module does without trying to guess from the file name.
SELECT * FROM pg_available_extensions; - And best yet, so you never have to answer this question again though you may have to answer newer questions: PostGIS backup/restore because extensions don't get backed up aside from the CREATE EXTENSION statement or whatever is marked as user editable data by teh extension packager.
- Better yet, pgAdmin III has an interface for it so you don't need to remember these commands except the unpackaged one, which sadly pgAdmin seems to be lacking in its arsenal.
All these benefits take some effort on the extension packager to make possible.
How does PostgreSQL know what versions of a package exist and which is the primary?
It knows by file name convension and the control file. For example, for postgis_topology, we have these files in the share/extension folder named:
postgis_topology.control postgis_topology--2.0.0a1.sql postgis_topology--2.0.0a1--2.0.0.sql postgis_topology--unpackaged--2.0.0a1.sql
PostgreSQL looks at this and now knows there exists a version 2.0.0a1 and a file that will migrate a 2.0.0 to 2.0.0a1. This is because I mislabeled the first version of the extension 2.0.0 though 2.0.0 is not released yet. This allows the packager to make possible both downgrade and upgrade paths. the sql files (except for the unpackaged), are the same scripts you would run in prior versions of PostgreSQL, except they are not allowed to contain BEGIN/COMMIT; clauses. So in short making a PostGIS extension that can only install new versions was relatively painless once you learned the nuances of json, control and make install script conventions of the extension model.
The control file is a text file that dictates what other extensions are required, what is the default version to install if none is specified, if an extension can be relocated to a different schema and if not, what schema should it be installed in. Below is an example. NOTE: my version has a a1 at the end since its an alpha release.
# postgis topology extension comment = 'postgis topology spatial types and functions' default_version = '2.0.0a1' relocatable = false schema = topology requires = postgis
The install from unpackaged is a special CREATE EXTENSION command that doesn't install new functionality, but bundles functions, tables etc. you already have in your database as an extension. You would need this feature for example if you installed PostGIS 2.0.0 not as an extension and want it to become an extension. In this scenario you have 900+ PostGIS functions floating about unaware of the fact that they are part of the same family. This command will christen them as members of The PostGIS family. In the case of PostGIS Topology family, we are talking about 70 someodd functions, types, and meta tables. Still a number too large to count on your fingers and toes.
Quickie Lessons Learned
- Allowing your extension to be uninstalled requires no extra coding. Yeh I can finally one day get rid of that uninstall postgis script I despise with a passion. It just works and won't allow you to drop if you have dependencies unless you unleash a DROP CASCADE.
- If your extension is not relocateable such as the case with topology, DO NOT INCLUDE A CREATE SCHEMA in your install script. The extension model creates the schema for you and get's mad when you try to recreate it again in your script.
- DO NOT PUT ALTER TABLE commands in your install script. It's fine for an upgrade script, but not an install script. strk was being cute and did this in topology so that he could distinguish between the old 1.* topology and the new 2.0. I got a cryptic error with this. Why it had no issue with the ALTER DOMAIN DROP CONSTRAINT ... is a bit of a mystery to me.
- If you are going to have an extension that is not relocateable and it has dependency on another extension, YOU ABSOLUTELY HAVE TO LIST THESE DEPENDENCIES IN YOUR control file. If you don't your extension will not install. The reason for this is when you mark an extension as non-reloacateable, PostgreSQL sets the schema to the non-relocateable extension schema completely ignoring the database's search_path. If you add dependencies to the control, it will also add to the search_path the schemas of the dependency extensions.
- Creating an unpackaged script when you have 70 functions to worry about looks daunting on the outset, but there is hope.
The
CREATE EXTENSION postgis_topology FROM unpackagedis all made possible by a script in the share/extension folder that has the name something likepostgis_topology--unpackaged--2.0.0a1.sqlHowever it looks very different from an install script in that the commands in it are of the form:
ALTER EXTENSION postgis_topology ADD FUNCTION ...;
repeat the recipe for every object that your package contains
When you are talking about 70 functions that's scary, and when 900+ with developers adding new ones daily, that is a nightmare unless you have a plan.
My new friend Sed
Sed and I have known each other for a while, but we have been in the past, casual interlopers. I dismissed him as a tool of those underground UNIX folks too in love with their cryptic commands to see the light of day and he dismissed me as a misguided window's user unequipped to appreciate the marvels of stream manipulation.
Then one day I had a problem that it seemed Sed might have the best answer to and a 1 line answer at that. I love one line answers which is why I love SQL and spatial SQL.
Problem: How do I convert Sandro's topology.sql install script file which has commands like:
CREATE TABLE topology.topology (
id SERIAL NOT NULL PRIMARY KEY,
name VARCHAR NOT NULL UNIQUE,
SRID INTEGER NOT NULL,
precision FLOAT8 NOT NULL,
hasz BOOLEAN NOT NULL DEFAULT false
);
CREATE OR REPLACE FUNCTION topology.ST_GetFaceEdges(toponame varchar, face_id integer)
RETURNS SETOF topology.GetFaceEdges_ReturnType
AS
$$
stuff here
$$
$$
LANGUAGE 'plpgsql' VOLATILE;
ALTER EXTENSION postgis_topology ADD TABLE topology.topology;
ALTER EXTENSION postgis_topology ADD FUNCTION topology.ST_GetFaceEdges(toponame varchar, face_id integer);
And Sed said, "I can do that with one line of code." More on that later
Using PostgreSQL Extensions
Lessons learned Packaging PostGIS Extensions: Part 2 Advanced
One of the great lessons learned in building PostGIS extensions is my rediscovery of SED. SED turned out to be mighty useful in this regard and I'll explain a bit in this article. Unfortunately there is still a lot I need to learn about it to take full advantage of it and most of my use can be summed up as monkey see, monkey scratch head, monkey do. In addition I came across what I shall refer to as Pain points with using the PostgreSQL Extension model. Part of which has a lot to do with the non-granular management of changes in PostGIS, the day to day major flux of changes happening in PostGIS 2.0 space, and my attempt at trying to creat upgrade freeze points amidst these changes. When PostGIS 2.0 finally arrives, the freeze points will be better defined and not change from day to day. So some of these issues may not be that big of a deal.
The Joy of SED: Building unpackaged extension install scripts
In the Packaging PostGIS Extensions Part 1, I mentioned a problem I had with converting a topology install script to an Extension unpackaged script. The idea of the extension unpackaged script is to package already installed loose functions, tables, types, operators,etc into a package. This would come about if you installed a contrib module the old fashioned way and then wanted to mark it as an extension so you could experience all the joys the extension model provides.
Problem: So the topology install script looked something like this:
CREATE TABLE topology.topology (
id SERIAL NOT NULL PRIMARY KEY,
name VARCHAR NOT NULL UNIQUE,
SRID INTEGER NOT NULL,
precision FLOAT8 NOT NULL,
hasz BOOLEAN NOT NULL DEFAULT false
);
CREATE OR REPLACE FUNCTION topology.ST_GetFaceEdges(toponame varchar, face_id integer)
RETURNS SETOF topology.GetFaceEdges_ReturnType
AS
$$
stuff here
$$
$$
LANGUAGE 'plpgsql' VOLATILE;
ALTER EXTENSION postgis_topology ADD TABLE topology.topology;
ALTER EXTENSION postgis_topology ADD FUNCTION topology.ST_GetFaceEdges(toponame varchar, face_id integer);
This little sed script worked well:
sql/$(EXTENSION)--unpackaged--$(EXTVERSION).sql: ../../topology/topology.sql
sed -e '/^CREATE \(OR REPLACE\|TRIGGER\|TYPE\|TABLE\|VIEW\)/!d;' \
-e 's/OR REPLACE//g' \
-e 's/CREATE\(.*\)/ALTER EXTENSION $(EXTENSION) ADD\1;/' \
-e 's/DEFAULT [a-zA-Z]\+//g' \
-e 's/\(BEFORE\|AS\)\(.*\)/;/' \
-e 's/(;/;/' \
-e 's/\\(;/;/' \
-e 's/;;/;/g' $< > $@
, though needs some slight modifications to work more seamlessly. To get it to work I had to make sure all the function arguments were on a single line in topology.sql. I've been struggling to get it to work with functions where the arguments are broken up in multiple lines. I've learned enough to know it's possible, but just haven't come up with the right sequence of sed to make it happen. This was a minor set back since most functions in PostGIS geometry, geography, raster, and topology have function args defined on a single line in there respective scripts so only about 10 or so need changing. It's just bothersome that you can create a valid install script that can't be converted to an unpackaged script. Any people with suggestions I'm all ears.
To summarize what this script does.
- The first sed -e uses the !d command to delete all lines that don't have a CREATE followed by REPLACE, TRIGGER,TYPE, TABLE, VIEW.
This basically just leaves the header lines of each object like:
CREATE OR REPLACE FUNCTION topology.ST_GetFaceEdges(toponame varchar, face_id integer)and chucks the bodies. - The second just wipes out any OR REPLACE that is left so we are left with:
CREATE FUNCTION topology.ST_GetFaceEdges(toponame varchar, face_id integer) - The third sed line replaces the word CREATE with
ALTER EXTENSION topologywhere $(EXTENSION) is a variable set to topology and then adds back in the FUNCTION and args. So my new line becomes:
ALTER EXTENSION topology ADD FUNCTION topology.ST_GetFaceEdges(toponame varchar, face_id integer) - The fourth sed line strips out all the DEFAULT values. In this particular set I have no default args but I do have some in other functions.
- The fifth line gets rid of BEFORE or AS and anything that comes after and replaces with a semicolon. This I needed because sometimes the AS is put on the first line of the object body and sometimes its now.
- The last sed command strips any duplicate semicolons
The Joy of SED: Building extension upgrade scripts
I developed a similar answer for creating an upgrade script and this one actually doesn't care about multilines etc. This worked great for topology, but for combining raster / postgis combo package I ran into some set backs. These set backs have more to do with limitations of extensions model than anything to do with SED. My script looked like this:
sql/$(EXTENSION)--2.0.0a2--$(EXTVERSION).sql: sql_bits/postgis_raster_upgrade_minor.sql
sed -e 's/BEGIN;//g' -e 's/COMMIT;//g' \
-e '/^\(CREATE\|ALTER\) \(CAST\|TYPE\|TABLE\|SCHEMA\|DOMAIN\|TRIGGER\).*;/d' \
-e '/^\(CREATE\|ALTER\|DROP\) \(CAST\|TYPE\|TABLE\|SCHEMA\|DOMAIN\|TRIGGER\)/,/\;/d' \
-e 's/^DROP \(AGGREGATE\|FUNCTION\) [\(IF EXISTS\)]*\(.*\);/ALTER EXTENSION $(EXTENSION) DROP \1 \2;DROP \1 IF EXISTS \2 ;/' \
$<< >> $@
Basically the intent was to create a micro upgrade script. The first line strips BEGIN and COMMIT clauses since the CREATE and ALTER Extension commands put in their own begin and commit.
Since PostGIS doesn't introduce any new complex types in theory for micro upgrades, I could avoid including CASTS, TABLES, SCHEMA, DOMAIN etc. creations. That is what the second line of the sed part does -- strip out all undroppable object types from the update that is all defined on a single line. The third line drops alls such things defined on multiple lines by deleting all phrases that start with CREATE ... up to the ;. It wouldn't work for functions since they could have ; in the body, but for CASTS types etc it works fine. The final sed command looks for AGGREGATE or FUNCTION drops and then adds a line before them to drop the AGGREGATE/FUNCTION from the EXTENSION. This is where my issue starts.
In the PostGIS 2.0 wind of changes, people are renaming function argument names every so often, changing AGGREGATES internals,
or dropping functions replacing them with equivalents that take default args.
Such changed require a DROP of the Aggregate or Function first if it exists. IF EXISTS works great since you don't have to worry
about the case of your script throwing an error if it doesn't exist. However, the ALTER EXTENSION
syntax does not support the DROP IF EXISTS, so it has to exist. For my older installs, the functions I am trying to drop may not exist.
If a object is part of an EXTENSION, it has to be dropped from the extension before you can drop it. This forces me to
use a DROP CASCADE clause, which I hate using because it could destroy user defined objects that aren't part of the extension. In those cases
I would prefer the update to fail rather than risking destroying user generated data. Keep in mind that in standard
release time, these deeper kind of changes wouldn't be allowed so might be a non-issue.