Table Of Contents
pgAdmin pgScript Intermediate
From the Editors
PostGIS 1.5.2 coming soon
Over the past two weeks, the PostGIS development team has been working hard to get out PostGIS 1.5.2 in time for the PostgreSQL 9.0 release. This release contains fixes allowing PostGIS to compile against 9.0. Due to an unfortunate turn of events, we missed the cut by a couple of days and are currently experiencing technical difficulties with the postgis.org website. These should be resolved soon and barring no further difficulties, we should have the final PostGIS 1.5.2 ready late this week.
On the plus side, we do have a PostGIS 1.5.2 rc1 available for download from our PostGIS Wiki Release Candidate Downloads section. Please feel free to test these out so that we have a smooth release.
Paul's related post is here
Here are the details of what is fixed:
- This is a bug fix release, addressing issues that have been
filed since the 1.5.1 release.
- Bug Fixes
- Loader: fix handling of empty (0-verticed) geometries in shapefiles.
(Sandro Santilli)
- #536, Geography ST_Intersects, ST_Covers, ST_CoveredBy and
Geometry ST_Equals not using spatial index (Regina Obe, Nicklas Aven)
- #573, Improvement to ST_Contains geography
- Loader: Add support for command-q shutdown in Mac GTK build (Paul Ramsey)
- #393, Loader: Add temporary patch for large DBF files
(Maxime Guillaud, Paul Ramsey)
- #507, Fix wrong OGC URN in GeoJSON and GML output (Olivier Courtin)
- spatial_ref_sys.sql Add datum conversion for projection SRID 3021
(Paul Ramsey)
- Geography - remove crash for case when all geographies are out of
the estimate (Paul Ramsey)
- #469, Fix for array_aggregation error (Greg Stark, Paul Ramsey)
- #532, Temporary geography tables showing up in other user sessions
(Paul Ramsey)
- #562, ST_Dwithin errors for large geographies (Paul Ramsey)
- #513, shape loading GUI tries to make spatial index when loading DBF only
mode (Paul Ramsey)
- #527, shape loading GUI should always append log messages
(Mark Cave-Ayland)
- #504 shp2pgsql should rename xmin/xmax fields (Sandro Santilli)
- #458 postgis_comments being installed in contrib instead of
version folder (Mark Cave-Ayland)
- #474 Analyzing a table with geography column crashes server
(Paul Ramsey)
- #581 LWGEOM-expand produces inconsistent results
(Mark Cave-Ayland)
- #471 DocBook dtd errors (Olivier Courtin)
- Fix further build issues against PostgreSQL 9.0
(Mark Cave-Ayland)
- #572 Password whitespace for Shape File to PostGIS
Import not supported (Mark Cave-Ayland)
- #603 shp2pgsql: "-w" produces invalid WKT for MULTI* objects.
(Mark Cave-Ayland)
- Enhancement
- #513 Add dbf filter to shp2pgsql-gui and allow uploading dbf only
(Paul Ramsey)
We should have windows binaries available a short time after release. Unfortunately we do not have the 64-bit windows build ready yet, so you still have to use the 32-bit version of PostgreSQL 9.0 if you need PostGIS on windows.
From the Editors
PostGIS 1.5.2 is out
The PostGIS development team is proud to announce the availability of PostGIS 1.5.2. Further details are on the postgis.org website PostGIS 1.5.2 release.
Leo and I are still working on the windows builds. As stated before the 32-bit builds will be out first. We are still preparing our 64-bit test environment on our new 64-bit laptop.
For those who are on 64-bit windows. Sami has some PostGIS 64-bit binaries for PostgreSQL 9.0 windows available on his blog. Though he just has the binaries available so you will need to use the other files from the 32-bit install.
To answer Sami's question, since he has asked it more than once:
I really can't understand why PostGIS developers still want to compile the whole stuff using msys/mingw and that kind of stuff. We have Visual C++ (yes, the compiler is available for free), everything compiles with it and you don't have to whine about how hard it is to compile stuff for Windows because it's not GNU.
There are 3 reasons:
- Believe it or not -- the PostGIS development crew is relatively small and most work on Unix or MacOSX which do compile under GNU. Each builds there own regression tests. We need to be able to test consistently on all platforms which means we need a devlopment environment that all regression tests will work on without too much fuss. As much of a pain as we whine about with mSys -- its the most like what everyone else uses and mimicks the environment most consistently.
- Supporting VC means supporting yet another set of make and configure files and yuck project files. I don't even think express can deal with solution files. etc. GEOS does it and it was a pain for them. I know because a while back I would point out all the issues I was having compiling under VC++ (not to mention I don't need VC++) -- cause I'm a webdeveloper -- so don't have it normally installed). It took Mat some time to revise packaged scripts to even get PostGIS to compile under VS. There are people that bicker, but no one steps up to the plate wanting to support VS/VC++.
- Leo and I are predominantly web developers and database professionals; frankly in my ideal world everything would be interpreted or Just in time compiled (JIT) by the server. MingW / VS slash anything that needs compiling is just a big pain however I look at it and they are of equal pain to me. I got out of desktop development so I wouldn't need to deal with compiling stuff.
Okay we have whined enough. There are talks in the PostGIS and GEOS group of switching to CMake and to have a process that builds said make / project files so that we can more easily support GNU and VS without hopefully not adding too much extra work on anyone's plate. We will see how that goes. Will we compile the 64-bit version under Msys64 or VS -- we would like to do both and compare the 2. :)
Basics
PgAdmin III 1.13 - change in plugin architecture and PostGIS Plugins Beginner
One of the neat changes already present in the PgAdmin III 1.13dev, is the change in plugin architecture. Version 1.13 dev allows for multiple plugin*.ini files. How does this work. Well if you have a plugins.d folder in your PgAdmin III version folder, it will read all the inis in that folder and load them as plugins.
Recall in PgAdmin III Plug-in Registration: PostGIS Shapefile and DBF Loader, we demonstrated how to load the PostGIS shapefile and dbf loader as a plugin in PgAdmin III, well this time we will demonstrate how to do it using PgAdmin version 1.13. Better yet, we'll show you the new and improved PgAdmin III Shapefile and DBF Loader in the works for PostGIS 2.0.
Installing PgAdmin 1.13 dev
Well PgAdmin 1.13 binaries, are not available on the PgAdmin official site, however they are packaged in the PostgreSQL 9.1 Alpha binaries. To use them, just extract the binaries and click on the PgAdmin3.exe in the bin folder. Most of our windows desktops can run them fine without any prior installation. However if you are on windows and they don't work out of the box, you may need to install the Visual C++ 2008 runtime libraries.
If you want to test out PostgreSQL 9.1 alpha on windows, you can do so by following our instructions listed in our Starting PostgreSQL in windows without install
Attached is our plugins.d which includes all the plugin inis for the plugins we will be describing
.Steps for installing plugins
- Extract binaries
- Create a folder in the PgAdmin III folder called - plugins.d
- To enable psql as a plugin, create a file -- doesn't matter what you call it, but something like psql.ini. You can copy the relative settings from your prior PgAdmin III install.
- To install the new PostGIS Shapefile Loader, copy the postgisgui folder from our PostGIS Windows Experimental Builds page into the bin folder of your PostgreSQL 9.1 Alpa.
- Create a postgis.shp2pgsql-gui.ini file in your plugins.d folder with the postgis specific ini contents.
; ; PostGIS shp2pgsql-gui (Windows): ; Title=PostGIS Shapefile and DBF loader 2.0 Command="$$PGBINDIR\postgisgui\shp2pgsql-gui.exe" -h "$$HOSTNAME" -p $$PORT -U "$$USERNAME" -d "$$DATABASE" -W "$$PASSWORD" Description=Open a PostGIS ESRI Shapefile or Plain dbf loader console to the current database. KeyFile=$$PGBINDIR\postgisgui\shp2pgsql-gui.exe Platform=windows ServerType=postgresql Database=Yes SetPassword=Yes
- Make sure your File->Options->bin folder is pointing at the bin of your extracted pg91 bin.
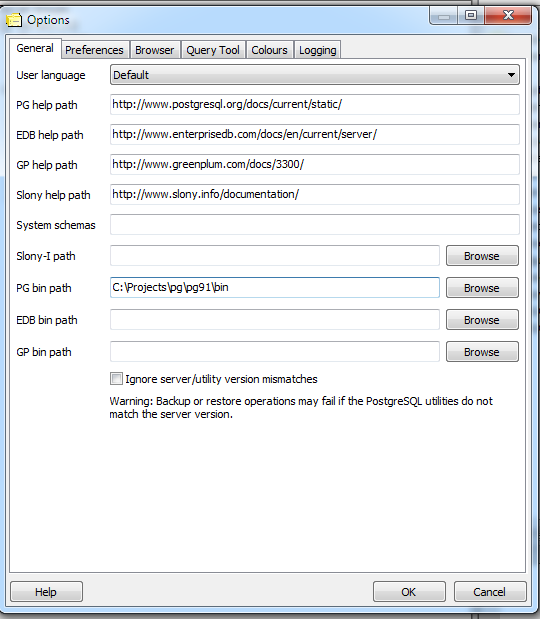
- Exit out of PgAdmin III and then reopen
- When you are done your plugins menu should look something like
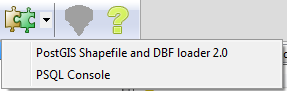
Take new PostGIS 2.0 Shapefile loader for a test drive
The great new feature of the upcoming loader is the ability to load multiple files at once. Here is what that looks like. For this exercise -- we pulled data from 2009 Tiger/Line Shapefiles and downloaded the State and Equivalent, and Military Installation. We also wanted to add in the 5-digit Zipcode tabulation area 2002 but that is a 600 mb file and we were running out of disk space on our test box.
- File browse as shown -- hmm hmm sadly in the current less than alpha version -- it seems you can only pick one file at a time so you have to do this twice.
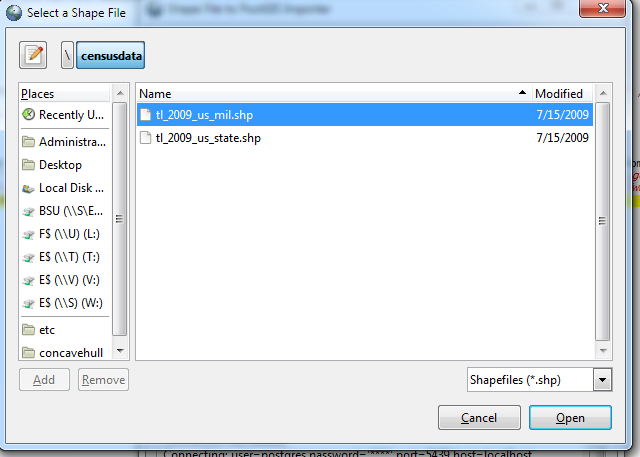
- Your screen should look something like this:
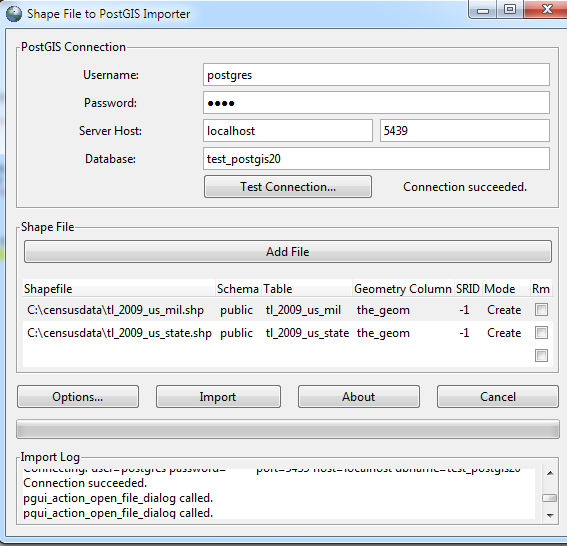
- Click into each cell you want to change (you can click the RM checkbox to remove a file). Your screen should look something like this
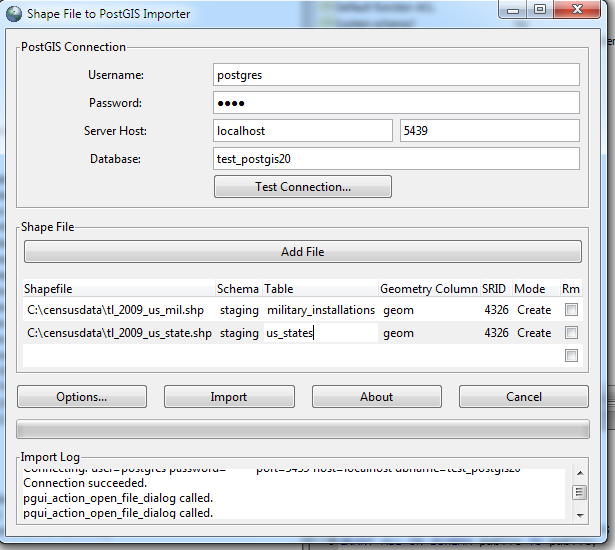
- Click options to set advanced options. Note that the options dialog applies to all files.
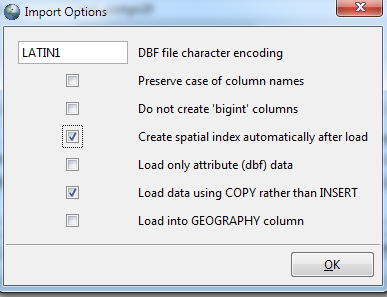
- Click the Import button.
PostGIS plugin for displaying geometries in PgAdmin III
Now there is another postgis plugin available written by Jérôme ROLLAND using MapWindow .NET and npgsql.NET. Unfortunately, this sadly doesn't work on Linux/Unix (mostly because Mapwindow.net apparently doesn't run under Mono.NET yet), so at the moment is a windows only plugin. You can download it from Plugin PgAdmin III : PostGISViewer suite. Jerome has written some other PostGIS pgAdmin III plugins including one that piggy-backs on FWTools to provide an interface for exporting PosTGIS data into various formats.
Here is a demonstration of the plugin in action and how to install it.
- Download the PostGISViewer.rar file and extract it into the bin folder of your PgAdmin III install (in this case the bin folder of your extracted PostgreSQL 9.1 Alpha). Note: rar file can be extracted witht eh free-ly available 7zip or WinRar
- Create an ini file in plugins.d -- lets call it postgis.postgisviewer.ini. With the contents described in Un plug-in pour PgAdmin III : PostGISViewer
- If you are running PostgreSQL 9.0 or 9.1, this tool doesn't seem to work unless you set the bytea_ouptut format of your database to escape:
ALTER DATABASE test_postgis20 SET bytea_output='escape';
Then exit out of PgAdmin
- This tool works by writing temp shapefiles to the Data folder of the PostGISViewer. Make sure the folder is not READ ONLY
- Open query window and type these queries:
SELECT ST_AsBinary(geom) As geom, GeometryType(geom), stusps FROM staging.us_states WHERE stusps IN('MA'); SELECT ST_AsBinary(m.geom) As geom, GeometryType(m.geom), m.fullname FROM staging.military_installations As m INNER JOIN staging.us_states As s ON ST_Intersects(s.geom,m.geom) WHERE s.stusps IN('MA'); - Move your main pgAdmin window such that you can see both the query window and the plugins menu as shown below:
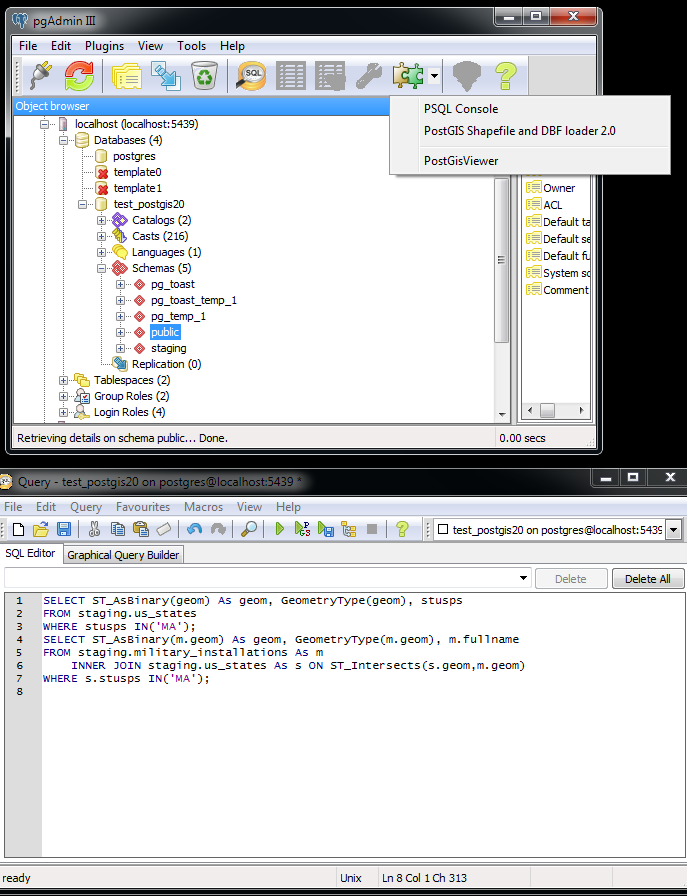
- Select the PostGIS Viewer Plugin option, and then click the feature identifier icon tool and you should see a screen that looks like this:
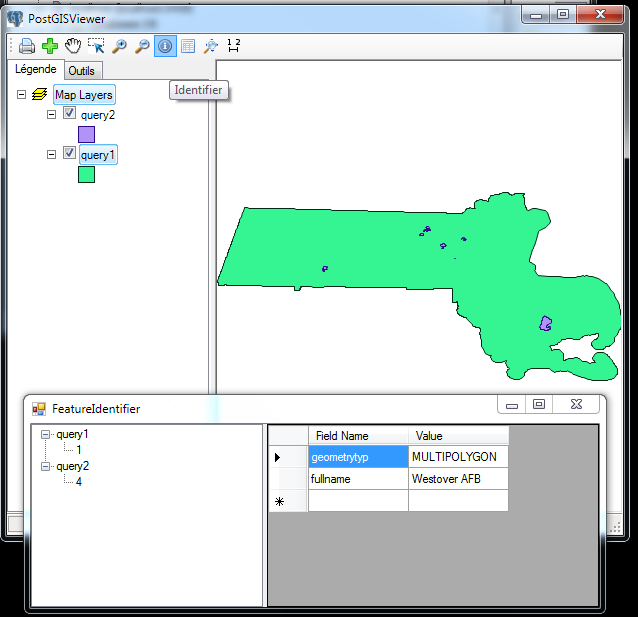
- The Outils tab has a whole slew of tools we didn't get a chance to test out.
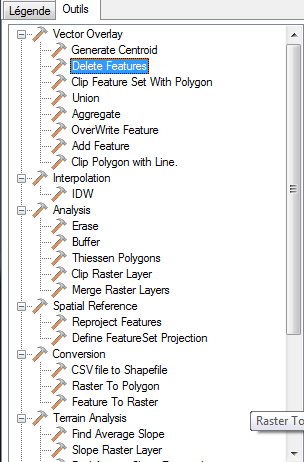
Note: you can also launch the viewer by selecting a postgis table from the schema tree. We didn't do this since most of our tables are fairly large and painful to load.
Basics
pgAdmin pgScript Intermediate
pgAdmin has this feature called a pgScript. Its a very simple scripting language for running tasks in a pgAdmin SQL window. The documentation is PgScript manual.
Why would you use it over say writing a plpgsql function?
One main reason we use it is to run quick ad-hoc batch jobs such as geocoding addresses and so forth. The benefit it has over running a stored function is that you don't have to run it as a single transaction.
This is important for certain kinds of tasks where you just want to run something in a loop and have each loop commit separately. To us the syntax with the @ resembles SQL Server Transact-SQL more than it does any PostgreSQL language. WhenI first saw pgScript I thought Wow PgAdmin talks Transact-SQL; now -- what will they think of next :).
Here is an example somewhat adapted from our upcoming Chapter 10: PostGIS in Action book. You would run a pgScript
from a PgAdmin Query window by clicking the  icon.
icon.
This code batch geocodes 500 records at a time committing every 500 records and repeats 20000 times.
DECLARE @I;
SET @I = 0;
WHILE @I < 20000
BEGIN
UPDATE addr_to_geocode
SET (rating, norm_address, pt)
= (g.rating,
COALESCE ((g.addy).address::text, '')
|| COALESCE(' ' || (g.addy).predirabbrev, '')
|| COALESCE(' ' || (g.addy).streetname,'')
|| ' ' || COALESCE(' ' || (g.addy).streettypeabbrev, '')
|| COALESCE(' ' || (g.addy).location || ', ', '')
|| COALESCE(' ' || (g.addy).stateabbrev, '')
|| COALESCE(' ' || (g.addy).zip, '')
,
g.geomout
)
FROM (SELECT DISTINCT ON (addid) addid, (g1.geo).*
FROM (SELECT addid, (geocode(address)) As geo
FROM (SELECT * FROM addr_to_geocode WHERE ag.rating IS NULL ORDER BY addid LIMIT 500) As ag
) As g1
-- 5 pick lowest rating
ORDER BY addid, rating) As g
WHERE g.addid = addr_to_geocode.addid;
SET @I = @I + 1;
PRINT @I;
END
Using PostgreSQL Extensions
Universal Unique Identifiers PostgreSQL SQL Server Compare Beginner
Universal Unique Identifiers are 16-byte / 32-hexadecimal digit (with 4 -s for separation) identifiers standardized by the Open Software Foundation.
The main use as far as databases go is to ensure uniqueness of keys across databases. This is important if you have multiple servers or disperate systems that need to replicate or share data and each can generate data on its own end. You want some non-centralized mechanism to ensure the ids generated from each server will never overlap. There are various open standards for generating these ids and each standard will tie the id based on some unique identifier of the computer or a namespace or just a purely random generator algorithm not tied to anything. Since this is a question often asked by users coming from Microsoft SQL Server, we will demonstrate in this article the same concept in Microsoft SQL Server and how you would achieve similar functionality in PostgreSQL.
I'm not sure how popular they are to use in other databases, but in SQL Server (and even in Microsoft Access), they are very popular, particularly if you need to synchronize data with various offices. If you come from Microsoft world, you probably know UUIDs by the term GUIDs, RowGUID, or data type uniqueidentifier or the thing that the NEWID() function in SQL Server generates, or in Microsoft Access when you choose AutoNumber and FieldSize = Replication ID. All the aforementioned use the standard 32-hexadecimal digit (with -) unique identifier. You may be wondering how you could get the same functionality in PostgreSQL.
PostgreSQL offers similar functionality via the uuid datatype. In additon there is a contrib module uuid-osp which provides various functions for auto-generating uuids. You can use these functions as default values in your table for columns that you need to have unique identifiers or just call them directly similar to what you do with SQL Server's NEWID() function. The main difference between the two is that SQL Server's text representation of the GUID is sometimes shown with {} (though not always) and sometimes as uppercase letters for presentation. PostgreSQL's native display representation doesn't have {} and usually uses lowercase letters. These are merely display representations (and can even be different depending on which display tool you are using). The display representation vs the actual type causes all sorts of confusion when people try to allocate space for them in there systems. SQL Server calls the type UniqueIdentifier and PostgreSQL calls the type uuid. Both types occupy 16-bytes of storage. For compatibility reasons with other software or databases, many use some stanardized text representation of them particularly for transport rather than using the native type. The text representation may require anywhere from 32 to 38 bytes (characters) contingent on if you add dashes or {}. Thus the confusion in storage requirements particularly when transporting to databases that don't have an equivalent of this type.
The GUID/UUID is not a text in either PostgreSQL or SQL Server system. They are native typs in both systems and are stored using 16 bytes. PostgreSQL does although have auto casts built in for converting uuids to text where as SQL Server requires an explicit cast to varchar.
As a side note: SQL Server does not support casting these to text even in SQL Server 2008 but PostgreSQL will happily cast to text or varchar. Just something to keep in mind if you need to create code that is compatible in both systems.
To demonstrate :
In SQL Server: If we try to do this:
SELECT NEWID() + '1234';
We get an error:
The data types uniqueidentifier and varchar are incompatible in the add operator.
However we can do this:
SELECT CAST(NEWID() As varchar(50)) + '1234'; which yields: 372F2ED9-37B0-4719-BC06-7ED9D730052A1234
As with most PostgreSQL contribs, the uuid-osp module can be installed in your PostgreSQL databases by running the SQL script share/contrib/uuid-ossp.sql which is located in your PostgreSQL install folder.
Similar example in PostgreSQL using the uuid-ossp contrib module and the ANSI-SQL standard || concatenate operator (NOTE: SQL Server uses + for concatenation):
SELECT uuid_generate_v1() || '1234' Yields: c3eeeb64-cd6c-11df-a41f-1b8d709f51b91234
We try to avoid relying on automatic casts whereever possible, just because you may get caught off guard if there are two automatic casts that are equally acceptible or there is no automatic cast at all in place. So to write the PostgreSQL in a more safe way and also to behave more like the SQL Server implementation, we would do
SELECT CAST(uuid_generate_v1() AS varchar(50)) || '1234' Using Unique identifiers as row ids
There are 2 general ways of assigning unique identifiers to rows in SQL Server and PostgreSQL, and a 3rd way specific to SQL Server.
- Explicit assignment in a stored proc or code: using SQL Server NEWID() function or one of PostgreSQL's uuid-osp contrib functions take your pick: uuid_generate_v1(), uuid_generate_v1mc(), uuid_generate_v4() functions or build your own.
- Setting the default value of the column to in SQL Server - SQL Server NEWID() or one of PostgreSQL's menu of uuid generator functions or build your own for either system.
- In SQL Server -- setting data type to uniqueidentifier and is RowGUID property of the column to Yes (similar in MS Access -- choosing data type AutoNumber and Size to ReplicationID): This last option only apply's to SQL Server and is really syntactic sugar for option 2.
Now I'm not sure what algorithm SQL Server uses in its NEWID(). Could be completely random in which case its most like PostgreSQL's uuid_generate_v4() function. At anyrate it doesn't really matter too much since all approaches will more or less guarantee unique identifiers across systems following the standard Unique Identifier form. PostgreSQL's uuid_generate_v1() generator is not completely random and generates a UUID that contains part of the Mac Address of the generating machine. This is nice in some sense because you could tie a record back to the machine that generated it, or not so nice from a security standpoint because it exposes a bit the identity of the machine that generated it. I tend to think of it as a nice informational feature particularly if you have several office servers and want to know the office that generated the record.
Below are some examples of using the UUID/GUID to assign identifiers in both systems. We'll cover both using the native type as well as using a text representation for ease of portability across systems that don't support the native types.
| Operation | PostgreSQL | SQL Server |
|---|---|---|
| Create a table that has a UUID/GUID type automatically assigned | |
|
| Create a table that has text representation of UUID/GUID as primary for easier transportation | |
|
| Encapsulate text id generator in a function | |
|
In the very last example, since we created wrapper functions with the same name, we can use the same application code base for both systems even if we want the identifier to be generated in our application for easier retrieval.
Now to take each for a test drive using our last variant:
| Action | PostgreSQL Output | SQL Server Output |
|---|---|---|
SELECT myfuncs.fn_mynewid(); | 8a0be412d21511df8757a3f328265df0 | 2b80fe3543e44fe9a378215d6e10fe4a |
| equip_id | equip_name ----------------------------------+------------ 51d4ca36d21611df8448a3b219d463c5 | Fax | equip_id equip_name -------------------------------- ------------- 9c2f44bfa60546b7ab1d95253c6070a2 Fax |
Special Feature
PostgreSQL 9.0 Cheat Sheet Overview
To celebrate the arrival of the long awaited PostgreSQL 9.0, we have prepared a multi-page PostgreSQL 9.0 cheat sheet that covers prior PostgreSQL constructs plus new 9.0 features. PDF version of this cheat sheet is available at PostgreSQL 9.0 Cheat sheet in PDF 8/12 by 11", PostgreSQL 9.0 Cheat sheet in PDF A4 and the PostgreSQL 9.0 Cheat sheet in HTML.
We took some advice from several readers and this time broke the cheatsheet into multiple pages. Hopefully you won't need magnifying glasses to read this one. We also switched to landscape and put all the examples at the end.
If you find any errors or anything major we left out, please let us know and we'll amend.