Table Of Contents
Allocating People into Groups with SQL the Sequel Advanced
Enable and Disable Vacuum per table Beginner
From the Editors
Beyond Nerds Bearing Gifts: The Future of the Open Source Economy
This week is a busy week for events. While PostgreSQL is having its PostgreSQL West conference in Seattle, the biggest Open Source GIS conference of the year is happening in Sydney, Australia FOSS4G 2009. Sadly given our schedule and the distances of the commutes, we couldn't make either conference.
Mateusz Loskot pointed out that the video is out for Paul Ramsey's FOSS4G 2009 Keynote speech on Beyond Nerds Bearing Gifts: The Future of the Open Source Economy. I think its a very important distinction Paul makes between selling software and selling a product, that a lot of people miss when trying to evaluate the solvency of open source software.
For those who don't know Paul, he's one of the co-founders of the PostGIS project and Refractions Research.
PostgreSQL Q & A
Allocating People into Groups with Window aggregation Intermediate
This is along the lines of more stupid window function fun and how many ways can we abuse this technology in PostgreSQL. Well actually we were using this approach to allocate geographic areas such that each area has approximately the same population of things. So you can imagine densely populated areas would have smaller regions and more of them and less dense areas will have larger regions but fewer of them (kind of like US Census tracts). So you have to think about ways of allocating your regions so you don't have a multipolygon where one part is in one part of the world and the other in another etc. Using window aggregation is one approach in conjunction with spatial sorting algorithms.
The non-spatial equivalent of this problem is how do you shove people in an elevator and ensure you don't exceed the capacity of the elevator for each ride. Below is a somewhat naive way of doing this. The idea being you keep on summing the weights until you reach capacity and then start a new grouping.
To test this idea out lets create a table of people and their weights. The capacity of our elevator is 750 kg.
CREATE TABLE passengers(passenger_name varchar(20) PRIMARY KEY, weight_kg integer);
INSERT INTO passengers(passenger_name, weight_kg)
VALUES ('Johnny', 60),
('Jimmy', 120),
('Jenny', 50),
('Namy', 20),
('Grendel', 500),
('Charlie', 200),
('Gongadin', 400),
('Tin Tin', 10),
('Thumb Twins', 10),
('Titan', 600),
('Titania', 550),
('Titan''s Groupie', 55);
SELECT carriage,COUNT(passenger_name) As cnt_pass,
array_agg(passenger_name) As passengers, SUM(weight_kg) As car_kg
FROM (SELECT passenger_name, weight_kg,
ceiling(SUM(weight_kg)
OVER(ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)/750.00) As carriage
FROM passengers) As congregation
GROUP BY carriage
ORDER BY carriage;
The result looks like
carriage | cnt_pass | passengers | car_kg
----------+----------+--------------------------------------------+--------
1 | 5 | {Johnny,Jimmy,Jenny,Namy,Grendel} | 750
2 | 4 | {Charlie,Gongadin,"Tin Tin","Thumb Twins"} | 620
3 | 1 | {Titan} | 600
4 | 2 | {Titania,"Titan's Groupie"} | 605
PostgreSQL Q & A
Allocating People into Groups with SQL the Sequel Advanced
In our prior story about allocating people with the power of window aggregation, we saw our valiant hero and heroine trying to sort people into elevators to ensure that each elevator ride was not over capacity. All was good in the world until someone named Frank came along and spoiled the party. Frank rightfully pointed out that our algorithm was flawed because should Charlie double his weight, then we could have one elevator ride over capacity. We have a plan.
What was wrong with our first try? Well we failed to realize that while the number of rides you need at each increment of weight has to be at least the ceiling of the sum divided by the capacity of the car, it can exceed that number. This approach we think works fine if you are simply counting people. If we had normally weighted people instead of some dwarfs and giants that may work fine. So if we wanted to fit at most 5 people per car we would do this. Note we also changed our window to something that is a bit shorter but equivalent in meaning.
To test this idea out lets recreate our table of characters (Charlie being a little fatter now). We want at most 5 people per car run.
CREATE TABLE passengers(passenger_name varchar(20) PRIMARY KEY, weight_kg integer);
INSERT INTO passengers(passenger_name, weight_kg)
VALUES ('Johnny', 60),
('Jimmy', 120),
('Jenny', 50),
('Namy', 20),
('Grendel', 500),
('Charlie', 400),
('Gongadin', 400),
('Tin Tin', 10),
('Thumb Twins', 10),
('Titan', 600),
('Titania', 550),
('Titan''s Groupie', 55) ;
SELECT carriage,COUNT(passenger_name) As cnt_pass,
array_agg(passenger_name) As passengers
FROM (SELECT passenger_name, weight_kg,
ceiling(COUNT(passenger_name)
OVER(ROWS UNBOUNDED PRECEDING)/5.0) As carriage
FROM passengers) As congregation
GROUP BY carriage
ORDER BY carriage;
The result looks like
carriage | cnt_pass | passengers
----------+----------+--------------------------------------------------
1 | 5 | {Johnny,Jimmy,Jenny,Namy,Grendel}
2 | 5 | {Charlie,Gongadin,"Tin Tin","Thumb Twins",Titan}
3 | 2 | {Titania,"Titan's Groupie"}
Of course this is not the problem we were trying to solve. We want to ensure that our car weights are at most 750 kg with giants in mind. So what to do. Sadly the power of window aggregates in PostgreSQL appears to fail us here but we can write a recursive query AKA (Recursive common table expression (CTE) with PostgreSQL 8.4. Sorry it looks kind of convoluted. The translation to this into spoken tongue is actually closer to what we said we were doing in the first place. If anyone can come up with a simpler way of achieving this, we'd like to know. I think there is a way to do this with a self-join, but haven't thought that far into it.
WITH RECURSIVE p1 As
(SELECT 1 As carriage, passenger_name, weight_kg, weight_kg As car_weight
FROM passengers
ORDER BY passenger_name LIMIT 1
),
congregation AS
(
SELECT carriage, passenger_name, weight_kg, car_weight
FROM p1
UNION ALL
SELECT np.carriage, np.passenger_name, np.weight_kg, np.car_weight
FROM
(SELECT CASE WHEN c.car_weight + p2.weight_kg <= 750
THEN c.carriage ELSE c.carriage + 1 END As carriage,
p2.passenger_name, p2.weight_kg,
CASE WHEN c.car_weight + p2.weight_kg <= 750
THEN c.car_weight + p2.weight_kg
ELSE p2.weight_kg END As car_weight
FROM passengers As p2 INNER JOIN
(SELECT carriage, passenger_name, weight_kg, car_weight
FROM congregation ORDER BY passenger_name DESC LIMIT 1)
As c ON (p2.passenger_name > c.passenger_name)
ORDER BY p2.passenger_name LIMIT 1) As np
)
SELECT carriage, COUNT(passenger_name) As cnt_pass,
array_agg(passenger_name) As passengers, SUM(weight_kg) As car_kg
FROM congregation
GROUP BY carriage;
Result
carriage | cnt_pass | passengers | car_kg
----------+----------+---------------------------------------------------+------
1 | 1 | {Charlie} | 400
2 | 1 | {Gongadin} | 400
3 | 5 | {Grendel,Jenny,Jimmy,Johnny,Namy} | 750
4 | 4 | {"Thumb Twins","Tin Tin",Titan,"Titan's Groupie"} | 675
5 | 1 | {Titania} | 550
PostgreSQL Q & A
Enable and Disable Vacuum per table Beginner
Vacuuming and analyzing is the process that removes dead rows and also updates the statistics of a table. As of PostgreSQL 8.3, auto vacuuming (the process that runs around cleaning up tables), is on by default. If you are creating a lot of tables and bulk loading data, the vacuumer sometimes gets in your way. One way to get around that is to disable auto vacuuming on the tables you are currently working on and then reenable afterward. You can also do this from the PgAdmin III management console.
Question:How do you disable and reenable auto vacuuming for a select table?
Solution: The SQL way
--disable auto vacuum
ALTER TABLE sometable SET (
autovacuum_enabled = false, toast.autovacuum_enabled = false
);
--enable auto vacuum
ALTER TABLE sometable SET (
autovacuum_enabled = true, toast.autovacuum_enabled = true
);
Solution: The PgAdmin III way
Navigate to the table in PgAdmin III explorer -> Select Table --> Properties and Click to go to Autovacuum tab
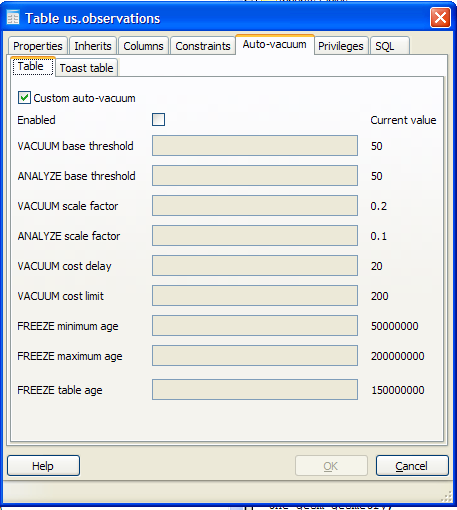
Note the other settings you can set in PgAdmin III. These can be set in SQL as well, and to see the SQL equivalent, simply set the settings, and switch to the PGAdmin III SQL tab. It will show the ALTER TABLE statement to run to make the change.
Basics
Lowercasing table and column names Beginner
This is an unfortunate predicament that many people find themselves in and does cause a bit of frustration. You bring in some tables into your PostgreSQL database using some column name preserving application, and the casings are all preserved from the source data store. So now you have to quote all the fields everytime you need to use them. In these cases, we usually rename the columns to be all lower case using a script. There are two approaches we have seen/can think of for doing this one to run a script that generates the appropriate alter table statements and the other is to update the pg_attribute system catalog table directly.
Lowercase column names
This is our preferred way, because it doesn't assume anything about the underlying structure of the pg_catalog tables and therefore less likely to cause damage. It also gives you history about what will be changed so in a sense is self-documenting. We are really big on self-documenting structures.
--This generates SQL you can then run - lower case column names - this puts the sql in a single record
-- suitable for running in a single EXECUTE statement or cut and paste from PgAdmin query window
SELECT array_to_string(ARRAY(SELECT 'ALTER TABLE ' || quote_ident(c.table_schema) || '.'
|| quote_ident(c.table_name) || ' RENAME "' || c.column_name || '" TO ' || quote_ident(lower(c.column_name)) || ';'
FROM information_schema.columns As c
WHERE c.table_schema NOT IN('information_schema', 'pg_catalog')
AND c.column_name <> lower(c.column_name)
ORDER BY c.table_schema, c.table_name, c.column_name
) ,
E'\r') As ddlsql;
-- As David Fetter kindly pointed out, this looks cleaner, returns one record per ddl and is more psql friendly
SELECT 'ALTER TABLE ' || quote_ident(c.table_schema) || '.'
|| quote_ident(c.table_name) || ' RENAME "' || c.column_name || '" TO ' || quote_ident(lower(c.column_name)) || ';' As ddlsql
FROM information_schema.columns As c
WHERE c.table_schema NOT IN('information_schema', 'pg_catalog')
AND c.column_name <> lower(c.column_name)
ORDER BY c.table_schema, c.table_name, c.column_name;
Lowercase table names
It goes without saying, that you may run into the same issue with table names. A similar trick works for that case.
--lower case table names - the PgAdmin centric way, single EXECUTE way
SELECT array_to_string(ARRAY(SELECT 'ALTER TABLE ' || quote_ident(t.table_schema) || '.'
|| quote_ident(t.table_name) || ' RENAME TO ' || quote_ident(lower(t.table_name)) || ';'
FROM information_schema.tables As t
WHERE t.table_schema NOT IN('information_schema', 'pg_catalog')
AND t.table_name <> lower(t.table_name)
ORDER BY t.table_schema, t.table_name
) ,
E'\r') As ddlsql;
-- lower case table names -- the psql friendly and more reader-friendly way
SELECT 'ALTER TABLE ' || quote_ident(t.table_schema) || '.'
|| quote_ident(t.table_name) || ' RENAME TO ' || quote_ident(lower(t.table_name)) || ';' As ddlsql
FROM information_schema.tables As t
WHERE t.table_schema NOT IN('information_schema', 'pg_catalog')
AND t.table_name <> lower(t.table_name)
ORDER BY t.table_schema, t.table_name;
--generates something like this
ALTER TABLE public."SPRINT" RENAME TO sprint;
Special Feature
Essential PostgreSQL DZone RefCardz is out
A while ago we wrote about DZone RefCards cheatsheets and how its a shame there isn't one for PostgreSQL. They are a very attractive and useful vehicle for learning and brushing up on the most important pieces of a piece of software or framework. Since that time we have been diligently working on one for PostgreSQL to fill the missing PostgreSQL slot. The fruits of our labor are finally out, and a bit quicker than we expected. The cheatsheet covers both old features and new features introduced in PostgreSQL 8.4. We hope its useful to many old and new PostgreSQL users.
The Essential PostgreSQL Refcard can be downloaded from Essential PostgreSQL http://refcardz.dzone.com/refcardz/essential-postgresql?oid=hom12841