Sunday, July 15. 2012
Printer Friendly
As we discussed in file_textarray_fdw Foreign Data Wrapper, Andrew Dunstan's text array foreign data wrapper works great for bringing in a delimited file and not having to worry about the column names until they are in.
We had demonstrated one way to tag the field names to avoid having to keep track of index locations, by using hstore and the header column in conjunction.
The problem with that is it doesn't work for jagged arrays. Jagged arrays are when not all rows have the same number of columns. I've jury rigged a small example
to demonstrate the issue. Luckily with the power of PostgreSQL arrays you can usually get around this issue and still have nice names for your columns. We'll demonstrate that too.
Continue reading "Foreign Data Wrap (FDW) Text Array, hstore, and Jagged Arrays"
Tuesday, July 10. 2012
Printer Friendly
Our new book PostgreSQL: Up and Running is officially out. It's available in hard-copy and e-Book version directly from O'Reilly,
Safari Books Online and available from Amazon in Kindle store. It should be available in hard-copy within the next week or so from other distributors.
Sadly we won't be attending OSCON this year, but there are several PostgreSQL talks going on. If you are speaking at a talk or other PostgreSQL related get together, and would like
to give out some free coupons of our book or get a free e-book copy for yourself to see if it's worth effort mentioning, please send us an e-mail: lr at pcorp.us .
Our main focus in writing the book is demonstrating features that make PostgreSQL uniquely poised for newer kinds of workflows with particular focus on PostgreSQL 9.1 and 9.2.
Part of the reason for this focus is our roots and that we wanted to write a short book to get a feel for the audience. We started to use PostgreSQL in 2001 because of
PostGIS, but were still predominantly SQL Server programmers. At the time SQL Server did not have a spatial component that integrated seamlessly with SQL.
As die-hard SQLers, PostGIS really turned us on. As years went by, we began to use PostgreSQL
not just for our spatial apps, but predominantly non-spatial ones as well that had heavy reporting needs and that we had a choice of platform.
So we came for PostGIS but stayed because of all the other neat features PostgreSQL had that we found lacking in SQL Server. Three off the bat
are arrays, regular expressions, and choice of procedural languages. Most other books on the market just treat PostgreSQL like it's any other relational database.
In a sense that's good because it demonstrates
that using PostgreSQL does not require a steep learning curve if you've used another relational database. We didn't spend as much time on these common features as we'd like to
in the book because it's a short book and we figure most users familiar with relational databases
are quite knowledgeable of common features from other experience. It's true that a lot of people coming to PostgreSQL are looking for cost savings,
ACID compliance, cross-platform support and decent speed
, but as PostgreSQL increases in speed, ease of features, and unique features, we think we'll be seeing more people migrating
just because its simply better than any other databases
for the new kinds of workflows we are seeing today -- e.g. BigData analysis, integration with other datasources, leveraging of domain specific languages in a more seamless way with data.
So what's that creature on the cover?

It's an elephant shrew (sengi) and is neither an elephant nor a shrew, but closest in ancestry to the elephant, sea cow, and aardvark.
It is only found
in Africa (mostly East Africa around Kenya) and in zoos. It gets its name from its unusually long nose which it uses for sniffing out insect prey and keeping tabs on its mate. It has some other unusual habits:
it's a trail blazer building trails it uses to scout insect prey and also builds escape routes on the trail it memorizes to escape from predators. It's monogamous, but prefers to keep separate quarters from its mate. Males
will chase off other males and females will chase off other females. It's fast and can usually out-run its predators.
Printer Friendly
UPDATE TO UPDATE: Bruce Momjian suggested replacing the dynamic set local sql with set_config. We've revised further to incorporate this suggestion. That got rid of our last pet peeve about this function. Thanks all.
Simon Bertrang proposed using set local which seems much nicer. We've updated our function using his revision.
One of PostgreSQL's nice features is its great support for temporal data. In fact it probably has the best support for temporal data than any other database. We'll see more of this power in PostgreSQL 9.2 with the introduction of date time range types.
One of the features we've appreciated and leveraged quite a bit in our applications is its numerous time zone aware functions. In PostgreSQL timestamp with time zone data type
always stores the time in UTC but default displays in the time zone of the server, session, user. Now one of the helper functions we've grown to depend on is
to_char() which supports timestamp and timestamp with timezone among many other types and allows you to format the pieces of a timestamp any way you like. This function is great except for one small little problem, it doesn't allow you to designate the display of the output timezone and always defaults to the TimeZone value setting of the currently running session.
This is normally just fine (since you can combine with AT TIMEZONE to get a timestamp only time that will return the right date parts, except for the case when you want your display to output the time zone -- e.g. EDT, EST, PST, PDT etc (timestamp without timezone is timezone unaware). In this article we'll demonstrate a quick hack to get around this issue. First let's take to_char for a spin.
Continue reading "Working with Timezones"
Sunday, July 01. 2012
Printer Friendly
In last article Finding Contiguous primary keys we detailed one of many ways of finding continuous ranges in data, but the approach would only work on higher-end dbs like Oracle 11G, SQL Server 2012, and PostgreSQL 8.4+. Oracle you'd have to replace the EXCEPT I think with MINUS. It wouldn't work on lower Oracle because of use of CTEs. It wouldn't work on lower SQL Server because it uses window LEAD function which wasn't introduced into SQL Server until SQL Server 2012. Someone on reddit provided a Microsoft SQL Server implementation which we found particularly interesting because - it's a bit shorter and it's more cross-platform. You can make it work with minor tweaks on any version of PostgreSQL, MySQL, SQL Server and even MS Access. The only downside I see with this approach is that it uses correlated subqueries which tend to be slower than window functions. I was curious which one would be faster, and to my surprise, this version beats the window one we described in the prior article. It's in fact a bit embarrassing how well this one performs. This one finished in 462 ms on this dataset and the prior one we proposed took 11seconds on this dataset. Without further ado. To test with we created a table:
CREATE TABLE s(n int primary key);
INSERT INTO s(n)
SELECT n
FROM generate_series(1,100000) As n
WHERE n % 200 != 0;
Continue reading "Contiguous Ranges of primary keys: a more cross platform and faster approach"
Friday, June 08. 2012
Printer Friendly
I recently had the need to figure out which ranges of my keys were contiguously numbered. The related exercise is finding gaps in data as well.
Reasons might be because you need to determine what data did not get copied or what records got deleted. There are lots of ways of accomplishing this, but this is the
first that came to mind. This approach uses window aggregates lead function and common table expressions, so requires PostgreSQL 8.4+
Continue reading "Finding contiguous primary keys"
Thursday, June 07. 2012
Printer Friendly
There is another new feature in 9.2 that doesn't get much press, and probably because it's hard to explain. It is a pretty useful feature if you are working with the new json type or the existing hstore type. In prior versions if you used a subquery and converted the rows to hstore or json the column names were not preserved. Andrew mentioned a back-port path for this issue in Upgradeable JSON. We described a workaround for this issue in Mail merging using hstore. The workaround for including PostGIS geometry in json record output as described in Native JSON type support wouldn't work as nicely without this enhancement. Here is an example to demonstrate.
Continue reading "PostgreSQL 9.2: Preserving column names of subqueries"
Monday, May 21. 2012
Printer Friendly
One new welcome feature in PostgreSQL 9.2 is the native json support and companion row_as_json and array_as_json functions. PostGIS also has a json function for outputting geographies and geometries in GeoJSON format which is almost a standard in web mapping.
Here is an example of how you'd use the new feature - create our test table
CREATE TABLE test(gid serial PRIMARY KEY, title text, geog geography(Point, 4326));
INSERT INTO test(title, geog)
VALUES('a'
, ST_GeogFromText('POINT(-71.057811 42.358274)'));
INSERT INTO test(title, geog)
VALUES('b'
, ST_GeogFromText('POINT(42.358274 -71.057811 )'));
Now with a command like this we can output all data as a single json object.
SELECT array_to_json(array_agg(t))
FROM test As t;
But there is a tincy little problem. Our geog outputs don't look anything like GeoJSON format. Our output looks like this:
[{"gid":1,"title":"a","geog":"0101000020E61000005796E82CB3C3
51C0E98024ECDB2D4540"}
,{"gid":2,"title":"b","geog":"0
101000020E6100000E98024ECDB2D45405796E82CB3C351C0"}]
To follow the GeoJSON standard, our geography object should output like this:
"geog":{"type":"Point","coordinates":[-71.057811000000001,42.358274000000002]}
Continue reading "PostgreSQL 9.2 Native JSON type support"
Printer Friendly
One of the things I'm excited about in PostgreSQL 9.2 are the new pg_dump section - pre-data, data, and post-data options and the exclude-table-data option. Andrew Dunstan blogged about this briefly in pg_dump exclude table data. What is also nice is that pgAdmin III 1.16 supports the section option via the graphical interface 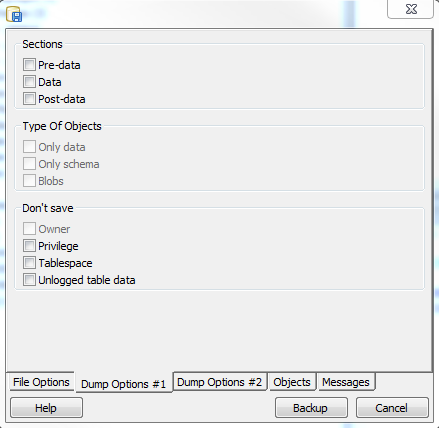 . I was a bit disappointed not to find the exclude-table-data option in pgAdmin III interface though.
The other nice thing about this feature is that you can use the PostgreSQL 9.2 dump even against a 9.1 or lower db and achieve the same benefit. . I was a bit disappointed not to find the exclude-table-data option in pgAdmin III interface though.
The other nice thing about this feature is that you can use the PostgreSQL 9.2 dump even against a 9.1 or lower db and achieve the same benefit.
The 9.2 pg_restore has similar functionality for restoring specific sections of a backup too.
So what is all this section stuff for. Well it comes in particularly handy for upgrade scripts. I'll first explain what the sections mean and a concrete example of why you want this.
- pre-data - this would be the table structures, functions etc without the constraints such as check and primary key and indexes.
- data -- it's uhm the data
- post-data - This is all constraints, primary keys, indexes etc.
Continue reading "PostgreSQL 9.2 pg_dump enhancements"
Wednesday, May 09. 2012
Printer Friendly
Last time we demonstrated how to query delimited text files using the fdw_file that comes packaged with PostgreSQL 9.1+, this time we'll continue our journey into Flat file querying Foreign Data Wrapper using an experimental foreign data wrapper designed for also querying delimited data, but outputting it as a single column text array table.
This one is called file_textarray_fdw and developed by Andrew Dunstan. It's useful if you are dealing with for example jagged files, where not all columns are not properly filled in for each record or there are just a ton of columns you don't want to bother itemizing before you bring in. The benefit is you can still query and decide how you want to break it apart. You can grab the source code from file_text_array_fdw source code. If you are on windows, we have compiled binaries in our Bag o' FDWs for both PostgreSQL 9.1 32-bit FDW for Windows bag and PostgreSQL 9.1 64-bit FDW for Windows bag that should work fine with the EDB installed windows binaries.
For other systems, the compile is fairly easy if you have the postgresql development libraries installed.
Continue reading "File FDW Family: Part 2 file_textarray_fdw Foreign Data Wrapper"
Thursday, May 03. 2012
Printer Friendly
Last time we demonstrated how to use the ODBC Foreign Data wrapper, this time we'll continue our journey into Foreign Data Wrapper land by demonstrating what I'll call the File FDW family of Foreign Data Wrappers. There is one that usually comes packaged with PostgreSQL 9.1 which is called fdw_file but there are two other experimental ones I find very useful which are
developed by Andrew Dunstan both of which Andrew demoed in PostgreSQL Foreign Data Wrappers and talked
about a little bit Text files from a remote source. As people who have to deal with text data files day in and out, especially ones from mainframes, these satisfy a certain itch.
- file_fdw - for querying delimited text files.
- file_fixed_length_fdw - this one deals with fixed length data. We discussed methods of importing fixed length data in Import Fixed width data. This is yet another approach but has the benefit that you can also use it to import just a subset of a file.
- file_text_array_fdw - this one queries a delimited file as if each delimiete row was a text array. It is ideal for those less than perfect moments when someone gives you a file with a 1000 columns and you don't have patience to look at what the hell those columns mean just yet.
In this article, we'll just cover the file_fdw one, but will follow up in subsequent articles, demonstrating the array and fixed length record ones.
Continue reading "File FDW Family: Part 1 file_fdw"
Sunday, April 15. 2012
Printer Friendly
As promised in our prior article: ODBC Foreign Data wrapper on windows, we'll demonstrate how to query SQL Server using the Foreign Data Wrapper. This we are testing on windows.
As far as querying SQL Server / PostgreSQL goes, the Foreign Data Wrapper still lacks many features that the SQL Server Linked Server approach provides.
The key ones we find currently lacking: ability to do updates and reference a table directly from server without knowing underlying structure. That said
the Foreign data Wrapper approach has possiblity to support a lot more data sources with ease. We'll demonstrate in subsequent articles using the www_fdw to query
web services which we've been playing a lot with and the often packaged in file_fdw. Enough of that let's start with a concrete example.
Warning, this is not production ready, but seems like a very promising start and with more testing can become very robust. Although we are demonstrating odbc_fdw on windows,
it is supported on Unix via the UnixODBC, but the data sources you can query will probably be different.
I'm really looking forward to how the FDW technology in PostgreSQL will push the envelop. I've been playing around with the www_fdw as well and been impressed how easily it is to
query webservices with SQL. A very ah-hah moment.
Continue reading "ODBC Foreign Data wrapper to query SQL Server on Window - Part 2"
Saturday, April 07. 2012
Printer Friendly
One of the things people have complained about for quite some time is that postgis is installed in the public schema by default and it's difficult to move after the fact. With now over 900 functions types, etc, in the 2.0.0 release that is a lot of cluttering of workspace. Now that postgis 2.0.0 is packaged as an extension, you can move all those functions etc. to another schema with the ALTER EXTENSION command. PgAdmin even throws a nice GUI on top to allow you to do this with some mouse maneuvering if you prefer the guided way. This might very well be my most favorite usability feature, because if things don't work out you can just move it back to public. I've been hesitant to do this before because well it was harder and I have a lot of 3rd party apps I work with and fear one of them hard-coded public.geometry somewhere. With extensions I can easily revert if it doesn't work out.
I've done this with some of my databases and been testing out how it works. So far so good. Here is how you do it.
CREATE SCHEMA postgis;
ALTER DATABASE your_db_goes_here SET search_path="$user", public, postgis,topology;
GRANT ALL ON SCHEMA postgis TO public;
ALTER EXTENSION postgis SET SCHEMA postgis;
On a somewhat unrelated side note aside from the fact it has to do with postgis not being in same schema as geometry table is someone mentioned in PostGIS newsgroup recently that is an issue if you are using conditional triggers. That is that if you have a conditional when trigger it can't find the geometry when you restore the database because of the way the restore process changes search_path.
I'm expecting the extension model to significantly simplify PostGIS upgrades in the future, because since the functions don't get backed up, they don't get in the way when you do a hard upgrade. Hard upgrade will simply reduce to just restoring your database.
Tuesday, April 03. 2012
Printer Friendly
Yap that's right. PostGIS 2.0.0 is finally out the door. It took us Two years and 2 months, a super long incubation for us, but we did it and just in time for Javier's Where 2.0 2.0 Talk.. Paul has some border-line R rated pictures of the birthing process.
We have windows 32 binaries posted for those adventurous enough to taste the cookies while they are hot. We are working on the windows 64-bit binaries. Those should be out tomorrow. We'll be working in the coming week to get the installers ready to put up so they are available via Stack Builder. We'll probably put up the 32-bit ones first, hopefully followed shortly by the 64-bit ones. You should see PostGIS 2.0.0 soon on Yum as well. Devrim is cooking :).
Tuesday, March 27. 2012
Printer Friendly
If you are looking for odbc fdw drivers for PostgreSQL 9.5 and 9.6 refer to this newer articleOne of the new features in PostgreSQL 9.1 that we've been meaning to try is the new foreign data wrapper support.
Now that we are in compile mode gearing up for releasing PostGIS 2.0.0 for windows (both 32 and 64-bit), we thought we'd give the odbc_fdw a try trying to compile on windows. Last we tried we weren't successful because
we couldn't get past the -lodbc required step.
It turns out there is an easy fix to the ODBC dependency issue and I'm not sure I changed the line right. In the makefile we changed -lodbc to -lodbc32. This was needed for both compiling 32-bit as well as the 64-bit. We compiled the 64-bit version under our Mingw-64 chain
and 32-bit under our old Mingw gcc 3.4.5. Sadly we still don't have our mingw64 (compile for windows 32-bit compile up yet). Our ming64 for windows 32 can compile the 9.2 development branch but not the 9.1.3. Go figure. Anyrate to make a long story short -- we have 32-bit binaries for PostgreSQL (you can use in VC++ builds) and 64-bit binaries as well that you can use for the VC++ EDB builds for those who are interested in experimenting.
PostgreSQL 9.1 Windows 32-bit ODBC FDW PostgreSQL 9.1 Windows 64-bit ODBC FDW
So far we've tried the PostgreSQL 64-bit data wrapper against a SQL Server 2005 DSN and it seems to work fine. Have yet to try it on other ODBC sources.
We'll write up a more detailed article describing how to make the connections.
There is one trick to getting Mingw64 compiled PostgreSQL extensions to work with the Windows 64-bit EDB builds, and that is that when you compile your PostgreSQL under mingw64,
you have to configure with option ----disable-float8-byval as we noted in our PostGIS Window 64 build instructions.
Saturday, March 10. 2012
Printer Friendly
UPDATE We have PostGIS 2.0.0 available for both 32-bit and 64-bit windows PostgreSQL. We are wroking on getting the installers out
This past week has been very nerve racking but also exciting. We have successfully compiled PostGIS under the mingw64 chain and built a PostGIS windows 64-bit
for 2.0 (and 1.5), that can install under the Enterprise Db VC++ 64-bit builds of PostgreSQL 9.1. We haven't tried on 9.0, but we assume that should be fairly trivial.
Note only that, but it passes most of the PostGIS battery of tests. We first want to thank a group of people which made this all possible:
- Andrew Dunstan we are greatly indebted to for making it possible to compile PostgreSQL under mingw64 tool chain. As much as people have whined
about wanting to compile PostGIS under a pure VC chain, this is not possible at this juncture just because a lot of the tests and other tool chains PostGIS uses for building
are too tied to the Unix build environment.
- We want to thank the generous folks who provided money for our campaign so that we could funnel time from paid consulting work to focus on this effort and to prove that every little bit counts.
- SpatiaLite developer Alessandro Furieri whose mingw64 compile instructions were invaluable to helping us overcome our GEOS and other compile obstacles. SpatiaLite (the OGC spatial extender for SQLite),uses much of the same plumbing that PostGIS uses under the hood, so many of the lessons he learned an provide could be put to use with our problems.
- To Paul Ramsey especially and other PostGIS devs for general moral support and helping us tackle some PostGIS specific issues when compiled with mingw64. Paul demonstrated that yes you can mix VC++ built components with MingW and steps on how to do it. Part of the reason for that is the newer mingw32 seemed to crash with GEOS compiled under mingw32. Though the mingw64 chain didn't have this issue once we overcame our compile obstacle. We may in the future compare and see if compiling Geos under VC++ provides better performance and will also get us closer to having it possible to compile PostGIS fully under VC++ if people choose to. For the time being having a single tool chain that we can extract and run with is most important. We are preparing a self-standing Mingw64 tool chain with all the components needed to build PostGIS already compiled so that windows users who want to help with PostGIS need only extract to have a fully functioning postGIS dev environment and we also plan to move our mingw32 build to mingw64 chain of tools.
We hope to have a 64-bit compiled download ready next week for PostGIS 2.0.0 beta3 for people to try out. We are working on some issues with the raster2pgsql and loader/dumper guis we compiled not working right, but the core PostGIS works just fine in 64-bit and the 32-bit loader tools work fine against a 64-bit install. One thing we did notice with the 64-bit PostgreSQL is that we
can set shared_buffers much higher than the 32-bit PostgreSQL windows. On windows we could never go beyond ~700MB without it not being able to start or crashing. With the 64-bit we were able to go to 2GB. Haven't tried higher yet. We hope this will prove to be a performance boost for tasks such as geocoding that reuse a lot of the same datasets and benefit a lot from share memory.
|


 PostGIS in Action
About the Authors
Consulting
PostGIS in Action
About the Authors
Consulting


