PostgreSQL 8.3 introduced a couple of new features that improves the processing of functions and makes plpgsql functions easier to write. These are as follows:
- The new ROWS and COST declarations for a function. These can be used for any PostgreSQL function written in any language. These declarations allow the function designer to dictate to the planner how many records to expect and provide a hint as to how expensive a function call is. COST is measured in CPU cycles. A higher COST number means more costly. For example a high cost function called in an AND where condition will not be called if any of the less costly functions result in a false evaluation. The number of ROWs as well as COST will give the planner a better idea of which strategy to use.
- RETURN QUERY functionality was introduced as well and only applies to plpgsql written functions. This is both an easier as well as a more efficient way of returning query results in plpgsql functions. Hubert Lubazeuwski provides an example of this in set returning functions in 8.3. We shall provide yet another example of this.
- Server configuration parameters can now be set on a per-function basis. This is useful say in cases where you know a function will need a lot of work_mem, but you don't want to give all queries accessing the database that greater level of worker memory or you are doing something that index scan just works much better than sequential scan and you want to change the planners default behavior only for this function.
- Scrollable Cursors in PL/pgSQL - this is documented in Declaring Cursor Variables
- Plan Invalidation - Merlin Moncure covers this in PostgreSQL 8.3 Features: Plan Invalidation so we won't bother giving another example of this. Basic point to take away from this is that in procedures where you have stale plans floating dependent on tables being dropped by a function, those plans will be automagically deleted so you don't have ghost plans breaking your function.
COST
One very useful use case where allowing to specify the costliness of a function comes in handy is in cost-based short-circuiting. By that we mean instead of a standard orderly short-circuiting WHERE condition such as (a AND b AND c) evaluating in order and exiting when it reaches the first part that returns a false, the planner evaluates each based on order of cost. E.g. if evaluating c is cheaper than a and b, it would evaluate c and if c evaluates to false, then a and b will never be evaluated. Prior to 8.3 all internal functions were assumed to have a COST of 1 and regular stored functions COST of 100 where COST is cost per row. This of cause is often not true since for example some operations are faster in plpgsql than sql and vice versa and some other functions are more efficient done in PLPerl and you as a designer of a function know the internals of it and how resource hungry it really is e.g. not all C or plpgsql functions are made the same. The 8.3 feature allows you more granular control of how this cost-basing is done. There are two caveats that are not outlined in the 8.3 CREATE FUNCTION help docs that we feel are important to note since it left us scratching our heads for a bit. We thank Tom Lane for pointing these out to us.
- The new COST functionality provides additional cost-based short-circuiting only in AND conditions, not OR conditions. Presumably PostgreSQL really only applies cost-based short-circuiting in AND clauses except for the case of constants
- Again cost-based short-circuiting applies only in WHERE clauses, not in the SELECT part.
To demonstrate the above - we provide here a fairly trivial example that makes clear the above points.
--Setup code
CREATE TABLE log_call
(
fn_name character varying(100) NOT NULL,
fn_calltime timestamp with time zone NOT NULL DEFAULT now()
)
WITH (OIDS=FALSE);
CREATE OR REPLACE FUNCTION fn_pg_costlyfunction()
RETURNS integer AS
$$
BEGIN
INSERT INTO log_call(fn_name) VALUES('fn_pg_costlyfunction()');
RETURN 5;
END$$
LANGUAGE 'plpgsql' VOLATILE
COST 1000000;
CREATE OR REPLACE FUNCTION fn_pg_cheapfunction()
RETURNS integer AS
$$
BEGIN
INSERT INTO log_call(fn_name) VALUES('fn_pg_cheapfunction()');
RETURN 5;
END$$
LANGUAGE 'plpgsql' VOLATILE
COST 1;
--- Now for the tests -
--No cost-based short-circuiting - planner evaluates in sequence the more
--costly fn_pg_costlyfunction() and stops
TRUNCATE TABLE log_call;
SELECT (fn_pg_costlyfunction() > 2 OR fn_pg_cheapfunction() > 2 OR 5 > 2);
--Pseudo Cost-based short-circuiting
-- planner realizes 5 > 2 is a constant and processes that
-- No cheap or costly functions are run.
-- No functions are forced to work in this test.
TRUNCATE TABLE log_call;
SELECT true
WHERE fn_pg_costlyfunction() > 2 OR fn_pg_cheapfunction() > 2 OR 5 > 2;
--Again planner goes for low hanging fruit - processes 2 > 5 first
-- no point in processing the functions.
--No functions are forced to work in this test.
TRUNCATE TABLE log_call;
SELECT true
WHERE fn_pg_costlyfunction() > 2 AND fn_pg_cheapfunction() > 2 AND 2 > 5;
--No Cost-based short-circuiting planner processes in order
--and stops at first true
-- only fn_pg_costlyfunction() is run
TRUNCATE TABLE log_call;
SELECT true
WHERE fn_pg_costlyfunction() > 2 OR fn_pg_cheapfunction() > 2 ;
--Cost-based short-circuiting
-- planner realizes fn_pg_costlyfunction() is expensive
-- fn_pg_cheapfunction() is the only function run even though it is second in order
TRUNCATE TABLE log_call;
SELECT true as value
WHERE (fn_pg_costlyfunction() > 2 AND fn_pg_cheapfunction() > 5 );
ROWS
Another parameter one can specify in defining a function is the number of expected ROWS. This is covered a little in Hans-Jürgen SCHÖNIG's Optimizing function calls in PostgreSQL 8.3. We feel more examples are better than fewer, so we will provide yet another example of how this can affect plan decisions.
--Create dummy people with dummy names
CREATE TABLE people
(
first_name character varying(50),
last_name character varying(50),
mi character(1),
name_key serial NOT NULL,
CONSTRAINT name_key PRIMARY KEY (name_key)
)
WITH (OIDS=FALSE);
INSERT INTO people(first_name, last_name, mi)
SELECT a1.p1 || a2.p2 As fname, a3.p3 || a1.p1 || a2.p2 As lname, a3.p3 As mi
FROM
(SELECT chr(65 + mod(CAST(random()*1000 As int) + 1,26)) as p1
FROM generate_series(1,30)) as a1
CROSS JOIN
(SELECT chr(65 + mod(CAST(random()*1000 As int) + 1,26)) as p2
FROM generate_series(1,20)) as a2
CROSS JOIN
(SELECT chr(65 + mod(CAST(random()*1000 As int) + 1,26)) as p3
FROM generate_series(1,100)) as a3;
CREATE INDEX idx_people_last_name
ON people
USING btree
(last_name)
WITH (FILLFACTOR=98);
ALTER TABLE people CLUSTER ON idx_people_last_name;
-- The tests
CREATE OR REPLACE FUNCTION fn_get_peoplebylname_key(lname varchar)
RETURNS SETOF int AS
$$
SELECT name_key FROM people WHERE last_name LIKE $1;
$$
LANGUAGE 'sql' ROWS 5 STABLE;
--The Test
VACUUM ANALYZE;
SELECT p.first_name, p.last_name, nkey
FROM fn_get_peoplebylname_key('M%') as nkey
INNER JOIN people p ON p.name_key = nkey
WHERE p.first_name <> 'E';
Nested Loop (cost=0.00..42.75 rows=5 width=11)
(actual time=10.171..22.140 rows=2560 loops=1)
-> Function Scan on fn_get_peoplebylname_key nkey (cost=0.00..1.30 rows=5 width=4)
(actual time=10.153..10.841 rows=2560 loops=1)
-> Index Scan using name_key on people p (cost=0.00..8.28 rows=1 width=11)
(actual time=0.002..0.003 rows=1 loops=2560)
Index Cond: (p.name_key = nkey.nkey)
Filter: ((p.first_name)::text <> 'E'::text)
Total runtime: 22.806 ms
The pgAdmin graphical explain plan shows nicely that a Nested loop strategy is taken.
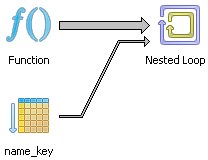
Now we try the same test again after setting ROWS to 3000.
CREATE OR REPLACE FUNCTION fn_get_peoplebylname_key(lname varchar)
RETURNS SETOF int AS
$$
SELECT name_key FROM people WHERE last_name LIKE $1;
$$
LANGUAGE 'sql' ROWS 3000 STABLE;
Hash Join (cost=1822.49..2666.14 rows=2990 width=11)
(actual time=66.680..70.367 rows=2560 loops=1)
Hash Cond: (nkey.nkey = p.name_key)
-> Function Scan on fn_get_peoplebylname_key nkey (cost=0.00..780.00 rows=3000 width=4)
(actual time=10.308..10.942 rows=2560 loops=1)
-> Hash (cost=1075.00..1075.00 rows=59799 width=11)
(actual time=56.317..56.317 rows=60000 loops=1)
-> Seq Scan on people p (cost=0.00..1075.00 rows=59799 width=11)
(actual time=0.007..27.672 rows=60000 loops=1)
Filter: ((first_name)::text <> 'E'::text)
Total runtime: 71.229 ms
By specifying the rows to a higher value, the planner changes strategies to a Hash Join from a nested loop. Why the hash join performs so much worse than the nested loop and it totally rejects using the index key in this case (even though the rows match closer to reality) is a little odd. Seems to suggest sometimes its best to lie to the planner, which is somewhat counter-intuitive.
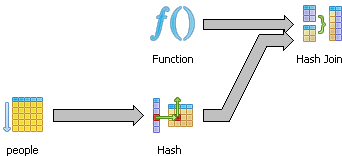
RETURN QUERY
One of the advantages of writing functions in plpgsql over writing it in say sql is that you can run dynamic sql statements in plpgsql and you can use named values. The downside was that you had to use the convoluted RETURN NEXT syntax which is both awkward and less efficient than the new RETURN QUERY. Below are two examples of using RETURN QUERY.
CREATE OR REPLACE FUNCTION fnpgsql_get_peoplebylname_key(lname varchar)
RETURNS SETOF int AS
$$
BEGIN
RETURN QUERY SELECT name_key
FROM people WHERE last_name LIKE lname;
END
$$
LANGUAGE 'plpgsql' STABLE;
CREATE OR REPLACE FUNCTION fnpgsql_get_peoplebylname(lname varchar, only_count boolean)
RETURNS SETOF int AS
$$
BEGIN
IF only_count = true THEN
RETURN QUERY SELECT COUNT(name_key)::int
FROM people WHERE last_name LIKE lname;
ELSE
RETURN QUERY SELECT name_key
FROM people WHERE last_name LIKE lname;
END IF;
END;
$$
LANGUAGE 'plpgsql' STABLE;
--To use --
SELECT *
FROM fnpgsql_get_peoplebylname('E%', true);
SELECT *
FROM fnpgsql_get_peoplebylname('E%', false);
Server Configuation Parameters per function
There are too many server configuration parameters one can use in functions to enumerate them. To demonstrate how these settings can be done, we revised our prior query and modified it mindlessly. NOTE don't construe any meaning to this function or the settings we chose. It is all in the name of "What goofy exercises can we concoct to demonstrate postgres features".
CREATE OR REPLACE FUNCTION fnpgsql_get_loop(lname varchar, numtimes integer)
RETURNS SETOF int AS
$$
DECLARE i integer := 0;
BEGIN
WHILE i < numtimes LOOP
RETURN QUERY SELECT p.name_key
FROM people p INNER JOIN people a ON p.name_key = (a.name_key + 1)
WHERE (p.last_name LIKE lname OR a.last_name LIKE lname);
i := i + 1;
END LOOP;
END;
$$
LANGUAGE 'plpgsql' STABLE
SET work_mem = 64
SET enable_hashjoin = false
SET enable_indexscan = true;
SELECT p.first_name, p.last_name, nkey
FROM fnpgsql_get_loop('M%',100) as nkey
INNER JOIN people p ON p.name_key = nkey
WHERE p.first_name <> 'E';